We describe a âconstant paceâ framework for video summarization via fast playback or temporal sub- sampling. The pace of the summary serves as a parameter.
CONSTANT PACE SKIMMING AND TEMPORAL SUB-SAMPLING OF VIDEO USING MOTION ACTIVITY Kadir A. Peker, Ajay Divakaran, Huifang Sun Mitsubishi Electric Research Laboratories, Murray Hill, NJ
ABSTRACT We describe a “constant pace” framework for video summarization via fast playback or temporal subsampling. The pace of the summary serves as a parameter that enables production of a video summary of any desired length. Earlier, we showed that the intensity of motion activity (or pace) of a video sequence is a good indication of its “summarizability.” Here we build on this notion by adapting the playback frame-rate or the temporal subsampling rate to the pace. Either the less active parts of the sequence are played back at a faster frame rate or the less active parts of the sequence are sub-sampled more heavily than are the more active parts, so as to produce a summary with constant pace. The basic idea is to skip over the less interesting parts of the video. Our technique is computationally simple and gives satisfactory results with surveillance and entertainment video.
1. INTRODUCTION Video summarization is useful in video browsing. Since the volumes of video content have become very large, it is a useful aid in browsing local content, and indispensable for browsing remote content since it leads to a more efficient use of available bandwidth. It is therefore applicable to remote rapid browsing of video for entertainment and surveillance in particular, and for any kind of video in general. Video abstraction can be defined as the creation of a compact representation of a video sequence[1]. Past work on video abstraction [1,5,6] has mostly focussed on using color features for video abstraction. It has mostly emphasized clustering based on color features, since color features are easy to extract and robust to noise. The summary itself consists of either a summary of the entire sequence or a set of interesting segments of the sequence or highlights. Pfeiffer et al [5] have used color and motion
and other features together to make summaries of video sequences. In [2], we hypothesized that since high or low action is in fact a measure of how much a video scene is changing, it is a measure of the “summarizability” of the video scene. For instance, a high speed car chase would certainly be less summarizable than a news-reader shot. Our experimental results showed that there is a strong correlation between intensity of motion activity and change in color characteristics from frame to frame. We thus proposed an algorithm to speed up existing colorbased summarization by confining color-based key frame extraction to difficult to summarize segments of the video by identifying the easy to summarize video segments using the intensity of motion activity. The “easy to summarize” video segments are so termed because they can be summarized by any constituent frame or segment chosen at random. In this paper, we propose a motion activity based temporal sub-sampling algorithm for video summarization that is applicable to the entire video sequence. Motion Activity Descriptor A human watching a video or animation sequence perceives it as being a slow sequence such as a “news reader shot”, or a fast paced sequence such as “goal scoring moment” or an action sequence etc. The MPEG-7 motion activity descriptor captures this intuitive notion of ‘intensity of action’ or ‘pace of action’ in a video segment [4]. 2. VIDEO SUMMARIZATION BY SUB-SAMPLING In this paper, we describe a sub-sampling based approach to video summarization. We argue that instead of uniform sub-sampling the video sequence to obtain the summary, we should adapt the sub-sampling rate to the intensity of motion activity by sub-sampling the less motion active segments heavily while sub-sampling highly
motion active segments less heavily. We present experimental results with diverse content that show that this leads to more effective summarization, since it allows the viewer to skip over the less active or “boring” parts. We finally investigate alternative motion activity based criteria for adaptive adjustment of playback speed for diverse content. Constant Activity Normalized Playback
Sub-Sampling
or
Sub-Sampling the Video Sequence - Another interpretation of such playback is that it is adaptive subsampling of the frames of the segment with the low activity parts being sub-sampled more heavily. This interpretation is especially useful if we need to summarize remotely located video, since we often cannot afford the bandwidth required to actually play the video back at a faster rate.
Activity
A brute force way of summarizing video is to play it back at a faster-than-normal rate. Note that it can also be viewed as uniform sub-sampling. Such a fast playback has the undesirable effect of speeding up all the portions equally thus making the high motion parts difficult to view, while not speeding up the low motion parts sufficiently. This suggests that a more useful approach to fast playback would be to play back the video at a speed that provides a viewable and constant level of motion activity. Thus, the low activity segments would have to be speeded up considerably to meet the required level of motion activity, while the high activity segments would need significantly less speeding up if at all. In other words, we would speed up the slow parts more than we would the fast parts. This can be viewed as adaptive playback speed variation based on motion activity, or activity normalized playback. Another interpretation could be in terms of viewability or “perceptual bandwidth.” The most efficient way to play the video is to make full use of the instantaneous perceptual bandwidth, which is what the constant activity playback achieves. We speculate that the motion activity is a measure of the perceptual bandwidth as a logical extension of the notion of motion activity as a measure of summarizability [2]. Let us make the preceding qualitative description more precise. To achieve a specified activity level while playing back video, we need to modify the activity level of the constituent video segments. We first make the assumption that the intensity of motion activity is proportional to the motion vector magnitudes. Hence, we need to modify the motion vectors so as to modify the activity level. There are two ways that we can achieve this: Increasing/Decreasing the Playback Frame-Rate – As per our earlier assumption, the intensity of motion activity increases linearly with frame rate. We can therefore achieve a desired level of motion activity for a video segment as follows: Playback frame rate =(Original Frame rate)*(Desired level of motion activity/original level of motion activity)
In both cases a and b, the summary length would then be given by Summary length=(Sum of frame activities)/desired activity Note that we have not yet specified the measure of motion activity. The most obvious choices are the average motion vector magnitude and the variance of the motion vector magnitude [3]. However, there are many variations possible, depending on the application. For instance, we could use the average motion vector magnitude as a measure of motion activity, so as to favor segments with moving regions of significant size and activity. As another example, we could use the magnitude of the shortest motion vector as a measure of motion activity, so as to favor segments with significant global motion. The average motion vector magnitude provides a convenient linear measure of motion activity. Decreasing the allocated playing time by a factor of two, for example, doubles the average motion vector magnitude. The ) average motion vector magnitude r of the input video of N frames can be expressed as:
rˆ = (
1 N )∑ ri , N i =1
where the average motion vector magnitude of frame i is ri. For a target level of motion activity rtarget in the output video, the relationship between the length Loutput of the output video and the length Linput of the input video can be expressed as:
Loutput =
rˆ rtarget
Linput
While playing back at a desired constant activity is possible in theory, in practice it would require interpolation of frames or slowing down the playback frame rate whenever there are segments that are higher in activity than the desired level. Such interpolation of frames would be computationally intensive and difficult. Furthermore, such an approach does not lend itself to generation of a continuum of summary lengths that
extends from the shortest possible summary to the original sequence itself. The preceding discussion motivates us to change the sampling strategy to achieve a guaranteed minimum level of activity as opposed to a constant level of activity, so we are able to get a continuum of summaries ranging from the sequence being its own summary to a single frame summary. With the guaranteed minimum activity method, we speed up or decrease allocated play time of all portions of the input video that are lower than the targeted minimum motion activity rtarget so that all these portions attain the targeted motion activity using the above formulations. The portions of the input video that exceed the targeted motion activity can remain unchanged. In one extreme, where the guaranteed minimum activity is equal to the minimum motion activity in the input video, the entire input video becomes the output video. When the guaranteed minimum activity exceeds the maximum motion activity of the input video, the problem reduces to the above constant activity case. In the other extreme, where the targeted level of activity is extremely high, the output video includes only one frame of the input video as a result of down-sampling or fast play. The length of the output video using the guaranteed minimum activity approach can be determined as follows. First, classify all of the frames of the input video into two sets. A first set Shigher includes all frames j where the motion activity is equal to or higher than the targeted minimum activity. The second set Slower includes all frames k where the motion activity is lower than the targeted motion activity. Then, the length of the input video is expressed by: Linput = Lhigher + Llower. The average motion activity
) rlower of frames j that
belong to the set Slower is
rˆlower = (
Nlower
1 N lower
) ∑ rj , j
and the length of the output converted is
r) Loutput = lower rtarget
Llower + Lhigher .
It is now apparent that the guaranteed minimum activity approach reduces to the constant activity approach because when Lhigher becomes zero, the entire input video needs to be processed.
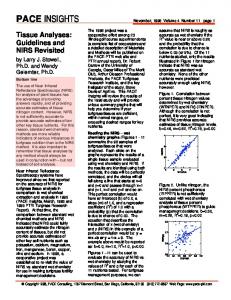
3. HOW FAST CAN YOU PLAY THE VIDEO While in theory it is possible to play the video back at infinite speed, the temporal Nyquist rate limits how fast it can be played without becoming imperceptible by a human observer. A simple way of visualizing this is to imagine a video sequence that captures the revolution of a stroboscope. At the point where the frame rate is equal to the rate of revolution, the stroboscope will seem to be stationary. Thus, the maximum motion activity level in the video segment determines how fast it can be played. Furthermore, as the sub-sampling increases, the video segment reduces to a set of still frames or a “slide show.” It is obvious that there is a cross-over point where it is more efficient to summarize the video segment using a slide show instead of with a video or “moving” summary. How to locate the cross-over point is an open problem. We hope to address this problem in our ongoing research. 4. EXPERIMENTAL PROCEDURE AND RESULTS We have tried our adaptive speeding up of playback using diverse content and got satisfactory results. We find that with surveillance footage of a highway (see Figure 1), using the average motion vector magnitude as the measure of motion activity, we are able to produce summaries that successfully skip across the parts where there is insignificant traffic, and focus on the parts with significant traffic. We get good results with the variance of motion vector magnitudes as well. We have been able to focus on parts with large vehicles, as well as on parts with heavy traffic. Note that our approach is computationally simple since it relies on simple descriptors of motion activity. We are currently working on detecting other anomalies. We have also tried our approach with sports video and with news content with mixed success. When viewing consumer video such as news or sports, skipping some parts at fast forward and viewing others at normal speed may be preferable to continuously changing the playback speed. For this purpose, we smooth the activity curve using a moving average and quantize the smoothed values (Figure 2). In our implementations, we used two-level quantization with the average activity as the threshold. For news and basketball (Figure 2 b and d), we used manually selected thresholds. For the golf video, the low activity parts are where the player prepares for his hit, followed by the high activity part where the camera follows the ball, or closes up on the player. For the news segment, we are able to separate the interview parts from the outdoor footage. For the soccer video, we see low activity segments before the game really starts, and also during the game where the game is interrupted. The basketball game, in contrast with soccer,
has a high frequency of low and high activity segments. Furthermore, the low activity parts are when the ball is in one side of the court and the game is proceeding, and the high activity occurs mostly during close-ups or fast court changes. Hence, those low activity parts should be played at normal speed, while some high activity parts can be skipped. In short, we can achieve a semantic segmentation of various content types using motion activity, and use domain knowledge to determine where to skip or playback at normal speed. Then, we can accordingly adapt our basic strategy described in Section 2, to different kinds of content.
Retrieval for Image and Video Databases, San Jose, January 1998. 7. Kadir A. Peker, “Video Indexing and Summarization using Motion Activity,” Ph.D. Thesis, NJIT, January 2001.
5. DISCUSSION AND CONCLUSIONS As illustrated by our results, video summarization using motion activity is especially useful in surveillance and similar applications in which the shots are long and the background is fixed. Note that in such applications, colorbased techniques are at a disadvantage since the semantics of the interesting events are much more strongly related to motion characteristics than to changes in color. Motion activity is also useful in summarization of other types of video such as news and sports. However, the general method described in this paper should be adapted to the desired content using domain knowledge.
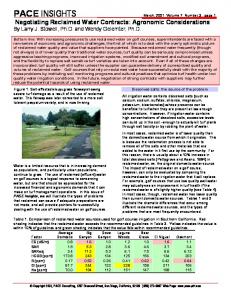
Figure 1. Illustration of adaptive sub-sampling approach to video summarization. The top row shows a uniform sub-sampling of the surveillance video, while the bottom row shows an adaptive sub-sampling of the surveillance video. Note that the adaptive approach captures the interesting events while the uniform subsampling mostly captures the highway when it is empty. The measure of motion activity is the average motion vector magnitude in this case.
(a)
7. REFERENCES 1. A. Hanjalic and H. J. Zhang, “An Integrated Scheme for Automated Video Abstraction Based on Unsupervised Cluster-Validity Analysis,” IEEE Trans. on Circuits and Systems for Video Technology, Vol. 9, No. 8, Dec. 1999. 2. A. Divakaran, K. A. Peker and H. Sun, “Video Summarization using Motion Descriptors,” Proc. SPIE Conf. on Storage and Retrieval for Media Databases, San Jose, CA, Jan 2001. 3. K. A. Peker and A. Divakaran, “Automatic measurement of intensity of motion activity,” Proc. SPIE Conf. on Storage and Retrieval for Media Databases, San Jose, CA, Jan 2001. 4. MPEG-7 Visual Committee Draft URL: http://www.cselt.it/mpeg/working_documents.htm official MPEG site 5. S. Pfeifer, R. Lienhart, S. Fischer, and W. Effelsberg, “Abstracting digital movies automatically,” J. Visual Comm. Image Representation, vol. 7, no. 4, pp. 345-353, Dec 1996. 6. V. Kobla, D. Doermann, and C. Faloutsos, “Developing high-level representations of video clips using videotrails,” Proc. SPIE Conf. on Storage and
(b)
(c)
(d)
Figure 2. Motion activity vs. frame number for four different types of video content, with the smoothed and quantized versions superimposed: a) Golf. b) News segment. c) Soccer. d) Basketball.