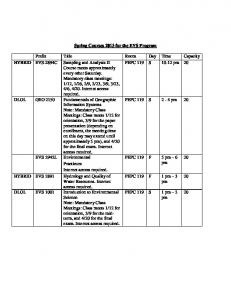
Course Code. : MCS-042 ... DATA COMMUNICATION AND COMPUTER NETWORK .... Only four bits of host suffix are needed to repr
Course Code : MCS-042 Course Title : DATA COMMUNICATION AND COMPUTER NETWORK
Question 1:What is congestion? How does leaky bucket algorithm control congestion? How are the drawbacks overcome in token bucket algorithm?
Hint: When too many packets are present in a subnet, performance degrades. This situation is called Congestion.
In any network when there is too much the data traffic at a node that the network slows down or starts loosing data, it is known as network congestion. It degrades quality of service and also can lead to delays, lost data or e.g. dropped calls on a telephone network.
when excess of data travels in a subnet or in node there will be a loss of data, this excess flow is know as network congestion.This demotes the performance in network e.g.improper delivery of fax
Two strategies for traffic shaping are available, leaky bucket algorithm and token bucket algorithm.
In leaky bucket algorithm each host is connected to the network by interface containing a leaky bucket, that is, a finite interval queue. If packet arrives at the queue when it is full, it is discarded. The queue is allowed to put a packet per clock tick on to the network. The input to the queue may be uneven i.e. bursty but the output is always at uniform rate, smoothing out bursts greatly reduces chances of congestion.
The leaky bucket algorithm enforces a rigid output pattern at the average rate, no matter how bursty the traffic is. For some application it is batter to allow the output to speed up somewhat when large burst arrive, so a more flexible algorithm is needed. One such algorithm is token bucket algorithm.
In token bucket algorithm, the leaky bucket holds the tokens, generated by a clock at a rate of one token every second. For a packet to be transmitted, it must capture and destroy one token. The token bucket algorithm provides a different kind of traffic shaping than the one with leaky bucket. The leaky bucket algorithm does not allow idle costs to save up permission to send large burst later. The token bucket algorithm does allow saving up n packets can be sent once, allowing some business in the output stream and giving faster responses to sudden burst of input. Another difference between the two algorithm is that the token bucket algorithm throws away tokens when the bucket fills up but never discard packets. In contrast, the leaky bucket algorithm discards packets when bucket fills up.
Question 2:What is routing? Discuss distance vector routing with the help of a subnet topology? Explain what are the different metrics used in this algorithm?
Hint: Routing is the process of selecting paths in a network along which to send network traffic. Routing is performed for many kinds of networks, including the telephone network (Circuit switching) , electronic data networks (such as the Internet), and transportation networks. For this the router uses a routing table, built, managed and updated by router itself by means of a routing algorithm.
Distance vector routing algorithmoperate by having each router maintain a table having best known distance to each destination and which lines to use to get there. These tables are updated by exchanging information with the neighbours. Each router maintains a routing table indexed by, and containing one entry for each router in the subnet. This entry contains two parts: the
1
preferred outgoing line to use for that destination and an estimate of the time or distance to that destination.
Consider a subnet in figure. It contains 6 routers A to F. the cost of each link is shown.
Initially it is assumed that each router knows cost to reach each of its neighbours. So they start by exchanging this information with their neighbours, so here A sends a distance vector to each of its neighbor i.e. BEF. What a router does after receiving a distance vector?. This is illustrated for the router B
A A
A 0 -
B 2 5
C 0
D 3
E 3 2
F 2 -
BA delay BC dalay is 2 is 5
Now estimation from B
2 A
0 5
C
8 C
5 A
4 A
2
Above Figure shows what B received from two of its neighbours A and C. now B use this vectors and the knowledge that it can reach A in 2 units and C in 5 units, it estimates or builds new routing table, B can reach A via its direct link whose cost is 2 so it marks 2 as cost and next hop as A in its table. B is itself. For C also direct link with cost 5 as A says it doesn’t have a path to C, for D, there is no path from A but C claims to have one with cost 3. So B can reach D via C with 3+5=8 units as cost of link. For E , A and C both have path. Via A B can reach A in 2 units and from A 3 more units so total 5 units. Via B, 5 units to reach B and 2 units from B to E so that 7 units. So path via A seems to be shorter, so it makes entry for E as 5 via A. similarly for F also.
Question 3: What is the IEEE 802.11 standard? Explain the role and function of each layer in IEEE 802.11 Protocol stacks?
Hint: IEEE 802 is a family of LAN standard. One of the protocol standard under IEEE 802 family is 802.11, which is specification of wireless LAN. It gives details about MAC and physical layer of wireless LAN
.
IEEE 802.11 protocol stack
Question 4:Explain the problems of hidden station and exposed station problem in wireless LAN. Also discuss the MACAW algorithm? Hint : The Hidden Station Problem
Figure 1 illustrates the hidden terminal problem. Suppose that node A wants to transmit to node B located at a distance x from A. By only sensing the medium, node A will not be able to hear transmissions by any node (C) in the dashed area denoted by A(x), and will start transmitting, leading to collisions at node B. This is the well known hidden terminal problem, where the hidden nodes are located in the area A(x).
The Exposed Station Problem
RTS/CTS handshake mechanism was introduced to wireless MAC layers to eliminate the hidden terminal problem. However, this mechanism introduces a new problem termed the exposed terminal problem. We assume here an RTS/CTS exchange so that the issue of hidden terminal is addressed. Let us consider Figure 2 and assume that node A wants to transmit to node B.
Hidden Station Vs Exposed Station: Which is worse?
In the case of hidden terminal problem, unsuccessful transmissions result from collisions between a transmission originated by a node such as A which cannot hear the on going transmissions to its corresponding node B. The probability of such a collision is proportional to the total number of terminals hidden from A.
In the case of exposed terminal, unsuccessful transmissions result from nodes such as A being prevented from transmitting, because their corresponding node is unable to send a CTS. Again
such unsuccessful transmissions are proportional to the number of exposed terminals. Both these events lead to degradation of a node's throughput.
The Multiple Access with Collision Avoidance for wireless LANs (MACAW) algorithm is used in IEEE 802.11 standard
to resolve the hidden nodes and exposed node problem, experienced in wireless communication. This algorithm
extends the original MACA algorithm and introduces the use of acknowledgment messages (ACK) for each successful reception of a packet.
Question 5: Differentiate between subnet and classless addressing? Hint: Subnet and Classless Addressing
As the Internet grew,the original classful addressing scheme became a limitation.On one hand,the IP address space was being exhausted.On the other hand,because all networks had to choose one of the three possible sizes,that means many addresses were unused.Two new mechanisms were invented to overcome the limitations,known as subnet addressing and classless addressing.These two addressing schemes are so closely related that they can be considered to be a part of single abstraction.The generalization is straight forward that means instead of having three distinct address classes,allow the division between prefix and suffix to occur on an arbitrary bit boundary.Let understand this situation with the help of an example,Consider a network that contains 9 hosts.Only four bits of host suffix are needed to represent all possible host values.However,a class C address,which has the fewest address hosts possible,devote eight bits to the host suffix.Classless addressing solves the problem by allowing an ISP(Internet Service Provider) to assign a prefix that is 28 bits long that means network can have up to 14 hosts.
Subnet addressing was initially used within large organizations.Classless addressing extended the approach to all Internet.
Consider an ISP that hands out prefixes. And suppose a customer of the ISP requests a prefix for a network that contains 55hostsclassful addressing requires a complete class C prefix only 4bits
5
of suffix are needed to represent all possible host valuesmeans 219of the 254possible suffixes would never be assigned most of the class C address space is wasted.
For example: classless addressing allows the ISP to assign a prefix that is 26bits long a suffix that is 6bits long
(a)
Construct the Hamming code for the bit sequence 10111100.
Hint: Hamming code is a type of error correcting code once a hamming code is generated for a message, it is transmitted to receiver and if a single bit error occurs it can be detected and corrected at receiver.
The process of generating hamming code is as given below. Message : 10111100
Hamming bit positions: 1,2,4,8 Data bits: remaining bits
12 11 10
9 8 7 6 5 4 3 2 1 1 0 1 1
1 1 0
0
Calculation for Hamming bit 1
Consider all odd bits i.e. 1,3,5,7,9,11. Its parity should be even. So humming bit 1 should be 0. For bit 2
Consider bits 2,3,6,7,10,11. So bit 2 should be 1
For bit 4 Consider bits 4,5,6,7,12. So bit 4 should be 1.
For bit 8 Check bits 9,10,11,12. So bit 8 = 1
So resulting code generated and transmitted is
12
11
10
987654321
101111101010 Question 6: (a) What is the various signal encoding techniques used as Physical layer
of LAN. Explain with example of each. Hint: Digital Data, Analog Signals [modem] Digital Data, Digital Signals [wired LAN]
Analog Data, Digital Signals [codec] –
Frequency Division Multiplexing (FDM)
– Wave Division Multiplexing (WDM) [fiber] – Time Division Multiplexing (TDM)
– Pulse Code Modulation (PCM) [T1] – Delta Modulation
Explain using diagram how the process of formation and pruning of a spanning tree takes place in a multicast routing?
Hint: Pruning is the method of removing all the paths that do not lead to the hosts that are members of the group. In a multicast routing when a process sends a multicast packet to a group, the first router examines its spanning tree and pruns it.
To do multicast routing, each router computes a spanning tree covering all router s in the subnet. E.g. in Fig (a) we have a subnet with two multicast groups 1 and 2. Some routers are attached to hosts that belong to one or both of these groups, as indicated in figure. A spanning tree for the leftmost router is shown in Fig(b).
When a process sends a multicast packet to a group, the first router examines its spanning tree and prunes it, removing all lines that doesn’t lead to hosts that are members of the group. Fig(c) shows pruned spanning tree for group 1. Similarly Fig(d) shows the pruned spanning tree for group 2. Multicast packets are forwarded only along the appropriate spanning tree.
Question 7: (a) Draw the waveform of (a) ASK (b) FSK (c) PSK for 1010101011. Hint: Wave form for ASK
Wave form for FSK
Wave form for PSK
(b) State Nagle’s algorithm and explain how it reduces the wastage of bandwidth?
Hint: Nagle’s algorithm says that when a TCP connection has outstanding data which has not been acknowledge then small segments cannot be sent to overcome this, firstly the outstanding data must be acknowledged. Instead, small amount of data are collected by TCP and sent in a
single segment when the acknowledgement arrives. On a slow WAN, where it is desired to reduce the no. of small datagrams, fewer segments are sent.
So nagle’s algorithm will improve throughput and avoid silly window syndrome. This will reduce the bandwidth used, when applied to on a badly congested network.
Question 8: (a)
What is the essence of DNS, how does it map to IP address?
Hint: Domain Name System (DNS) is a database system that translates a computer's fully qualified domain name into an IP address.
Networked computers use IP addresses to locate and connect to each other, but IP addresses can be difficult for people to remember. For example, on the web, it's much easier to remember the domain name www.amazon.com than it is to remember its corresponding IP address (207.171.166.48). DNS allows you to connect to another networked computer or remote service by using its user-friendly domain name rather than its numerical IP address. Conversely, Reverse DNS (rDNS) translates an IP address into a domain name.
Each organization that maintains a computer network will have at least one server handling DNS queries. That server, called a name server, will hold a list of all the IP addresses within its network, plus a cache of IP addresses for recently accessed computers outside the network. Each computer on each network needs to know the location of only one name server. When your computer requests an IP address, one of three things happens, depending on whether or not the requested IP address is within your local network:
If the requested IP address is registered locally (i.e., it's within your organization's network), you'll receive a response directly from one of the local name servers listed in your workstation configuration. In this case, there usually is little or no wait for a response. •
If the requested IP address is not registered locally (i.e., outside your organization's network), but someone within your organization has recently requested the same IP address, then the local name server will retrieve the IP address from its cache. Again, there should be little or no wait for a response. •
If the requested IP address is not registered locally, and you are the first person to request information about this system in a certain period of time (ranging from 12 hours to one week), then the local name server will perform a search on behalf of your workstation. This search may involve querying two or more other name servers at potentially very remote locations. These queries can take anywhere from a second or two up to a minute (depending on how well connected you are to the remote network and how many intermediate name servers must be contacted). Sometimes, due to the lightweight protocol used for DNS, you may not receive a response. In these cases, your workstation or client software may continue to repeat the query until a response is received, or you may receive an error message. •
(b)
Explain the concept of Triple DES through illustrations?
Hint: Triple DES is based on the DES (Data Encryption Standard) algorithm, therefore it is very easy to modify existing software to use Triple DES. It also has the advantage of proven reliability and a longer key length that eliminates many of the attacks that can be used to reduce the amount of time it takes to break DES. However, even this more powerful version of DES may not be strong enough to protect data for very much longer. The DES algorithm itself has become obsolete and is in need of replacement
Triple DES is another mode of DES operation. It takes three 64-bit keys, for an overall key length of 192 bits. In Stealth, you simply type in the entire 192-bit (24 character) key rather than
entering each of the three keys individually. The Triple DES DLL then breaks the user-provided key into three subkeys, padding the keys if necessary so they are each 64 bits long. The procedure for encryption is exactly the same as regular DES, but it is repeated three times, hence the name Triple DES. The data is encrypted with the first key, decrypted with the second key, and finally encrypted again with the third key.
Triple DES runs three times slower than DES, but is much more secure if used properly. The procedure for decrypting something is the same as the procedure for encryption, except it is executed in reverse. Like DES, data is encrypted and decrypted in 64-bit chunks. Although the input key for DES is 64 bits long, the actual key used by DES is only 56 bits in length. The least significant (right-most) bit in each byte is a parity bit, and should be set so that there are always an odd number of 1s in every byte. These parity bits are ignored, so only the seven most significant bits of each byte are used, resulting in a key length of 56 bits. This means that the effective key strength for Triple DES is actually 168 bits because each of the three keys contains 8 parity bits that are not used during the encryption process.