Journal of Cognitive Psychology, 2015 http://dx.doi.org/10.1080/20445911.2014.1000918
Positional character frequency and word spacing facilitate the acquisition of novel words during Chinese children’s reading Feifei Liang1,2, Hazel I. Blythe3, Chuanli Zang1, Xuejun Bai1, Guoli Yan1, and Simon P. Liversedge3 Downloaded by [Winchester School of Art] at 01:51 19 May 2015
1
Academy of Psychology and Behavior, Tianjin Normal University, Tianjin, China School of Education Science, Tianjin Normal University, Tianjin, China 3 School of Psychology, University of Southampton, Southampton, UK 2
Children’s eye movements were recorded to examine the role of word spacing and positional character frequency on the process of Chinese lexical acquisition during reading. Three types of two-character novel pseudowords were constructed: words containing characters in positions in which they frequently occurred (congruent), words containing characters in positions they do not frequently occur in (incongruent) and words containing characters that do not have a strong position bias (balanced). There were two phases within the experiment, a learning phase and a test phase. There were also two learning groups: half the children read sentences in a word-spaced format and the other half read the sentences in an unspaced format during the learning phase. All the participants read normal, unspaced text at test. A benefit of word spacing was observed in the learning phase, but not at test. Also, facilitatory effects of positional character congruency were found both in the learning and test phase; however, this benefit was greatly reduced at test. Furthermore, we did not find any interaction between word spacing and positional character frequencies, indicating that these two types of cues affect lexical acquisition independently. With respect to theoretical accounts of lexical acquisition, we argue that word spacing might facilitate the very earliest stages of word learning by clearly demarking word boundary locations. In contrast, we argue that characters’ positional frequencies might affect relatively later stages of word learning.
Keywords: Children; Positional character frequency; Word learning; Word spacing.
Words are perceptually salient in alphabetic writing systems (e.g., English texts) as a result of word spacing. Previous studies have shown that the removal of word spacing is highly disruptive to alphabetic reading (e.g. English text, see Morris,
Rayner, & Pollatsek, 1990; Perea & Acha, 2009; Pollatsek & Rayner, 1982; Rayner, 1998; Rayner, Fischer, & Pollatsek, 1998). By contrast, Chinese script is normally printed as a continuous string of characters, where there are only small spaces
Correspondence should be addressed to Simon P. Liversedge, School of Psychology, Shackleton Building, University of Southampton, Highfield, Southampton SO17 1BJ, UK. E-mail:
[email protected] The authors would like to thank Raymond Bertram, Kevin Paterson and an anonymous reviewer for their helpful comments on an earlier version of this manuscript. The authors also would like to thank for the great support from Center of Collaborative Innovation for assessment and Promotion of National Mental Health. No potential conflict of interest was reported by the authors. The work described in this article was supported by the Recruitment Program of Global Experts (1000 Talents Award from Tianjin); Natural Science Foundation of China [grant number 31100729], [grant number 81471629]; the Doctoral Scientific Research Foundation of Tianjin Normal University [grant number 52ww1409]; a postgraduate scholarship from the China Scholarship Council. © 2015 Taylor & Francis
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
2
LIANG ET AL.
between characters, and these are the same size regardless of whether they appear between or within words. Other than punctuation marks between characters, there is no other visual word boundary information to help Chinese readers segment and identify the words within sentence contexts (Li, Rayner, & Cave, 2009; Zang, Liversedge, Bai, & Yan, 2011). In addition, Chinese words have different lengths, typically ranging from one to four characters. The lack of visual word segmentation cues (such as word spacing), as well as the variation in word length, leads to an intriguing but fundamental theoretical question in relation to Chinese reading: How do Chinese readers segment character strings to identify words? There has been an amount of research to examine the cognitive processes underlying Chinese word segmentation (e.g., Bai, Yan, Liversedge, Zang, & Rayner, 2008; Blythe et al., 2012; Li et al., 2009; Liang et al., 2014; Shen et al., 2012; Wu, Slattery, Pollatsek, & Rayner, 2008; Yen, Radach, Tzeng, & Tsai, 2012; Zang, Liang, Bai, Yan, & Liversedge, 2013), however, most of these studies are examinations of skilled adult readers (though see Blythe et al., 2012; Zang et al., 2013). The dearth of studies investigating processes underlying children’s reading is unfortunate, given that the limited number of experiments that have been carried out in this area have provided insight into differences and similarities in aspects of reading between children and adults (for a review, see Blythe & Joseph, 2011; see also Reichle et al., 2013). In this experiment, we endeavour to make a contribution to current understanding of the usage of word segmentation cues by Chinese children during reading, and how such cues might facilitate the acquisition of representations for new words in the mental lexicon. There are thought to be three stages of cognitive processing that underpin lexical acquisition: triggering, lexical configuration and lexical engagement (Gaskell & Dumay, 2003; Hoover, Storkel, & Hogan, 2010; Leach & Samuel, 2007; Storkel, Armbrüster, & Hogan, 2006; Storkel & Lee, 2011). When a word is presented, the relevant orthographic, phonological and semantic representations are activated rapidly. The triggering mechanism is considered to determine whether the input exactly matches an existing lexical representation or not (Leach & Samuel, 2007). In the case of a known word being encountered, it will completely match an existing representation, so that the word can be recognised accurately. In the case of a novel word, there is no existing
cognitive representation that matches the novel input entirely; this leads to a mismatch, which then triggers a new lexical representation to be formed (e.g., Carpenter & Grossberg, 1987; Gupta & MacWhinney, 1997). Once the formation of a new lexical representation has been triggered, the configuration process then begins. The process of configuration involves storage and the update of phonological, orthographic and semantic information with the new lexical entry. As the novel representation is activated through additional, repeated encounters with the word during reading, the reader’s knowledge about that word (e.g., its sound, spelling, meaning and syntactic roles) becomes increasingly comprehensive (Capone & McGregor, 2005; Gershkoff-Stowe, 2002; Leach & Samuel, 2007). Previous studies have argued that these first two components (triggering and configuration) of lexical acquisition occur relatively rapidly (within an hour in Gaskell & Dumay’s, 2003 study). The third component of novel word learning is referred to as lexical integration (Gaskell & Dumay, 2003). Lexical integration involves the dynamic process of forming links between the newly created representation and other existing lexical and sublexical representations (Gaskell & Dumay, 2003; Leach & Samuel, 2007). Once the new representation and the links are stable, the new word is considered to have been mastered (Leach & Samuel, 2007). In contrast to the first two components (triggering and configuration), the process of lexical integration seems to be more extended (over several days in Gaskell & Dumay’s study, 2003), and does not rely on additional exposures to the novel input. It is worth noting here that this theoretical description of lexical acquisition is based on experimental data concerning spoken word acquisition (e.g., Storkel et al., 2006; Storkel & Lee, 2011). Those studies typically presented new vocabulary within story contexts, and do not directly deal with the issue of word segmentation. To the best of our knowledge, there have been no studies, to date, that have used measures of eye movements to assess word learning during natural silent reading. In the present study, eye movement recordings were used to investigate readers’ processing of two different word segmentation cues when learning novel Chinese words when encountered within sentence contexts. Although the theoretical models of lexical acquisition that are described here are based on alphabetic languages (predominantly English),
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
we still consider this framework to be both useful and relevant with respect to lexical acquisition during Chinese reading. Recall, however, that words in Chinese text are not as visually salient as in English text given the lack of word spacing. Thus, Chinese readers have to accurately segment the novel words within sentence contexts before the learning process can occur. Specifically, the reader must determine which characters comprise the new word before they are able to accurately determine that it is a new word—segmentation must precede the triggering process. Word segmentation seems, therefore, to be very important for Chinese readers to learn novel words within contexts. Two recent studies have examined whether or not there were any developmental changes between beginning readers and skilled adult readers of Chinese when segmenting the text into words (e.g., Blythe et al., 2012; Zang et al., 2013). For example, Zang et al. (2013) investigated how Chinese children (in third grade, eight to nine years old) and adults were influenced by interword spacing during the process of word identification in normal reading. Participants’ eye movements were recorded when reading sentences in both wordspaced and traditional, unspaced formats. The results showed that interword spacing reduced both children’s and adults’ first pass reading times. Importantly, this facilitatory effect was larger for children than for adults, indicating a more substantial benefit to children’s ongoing lexical processing. Another relevant study by Blythe et al. (2012) compared the role of word spacing on Chinese lexical acquisition between child (in second grade, seven to eight years old) and adult readers; specifically, they examined whether a spacing manipulation would facilitate the formation of novel word representations. Two-character pseudowords were embedded into explanatory sentence contexts, and these were presented across two experimental phases—a learning phase and a test phase (the same pseudowords were presented in each phase, but the sentence contexts varied between phases). Participants were divided into two learning groups: one group received wordspaced text in the learning phase, whereas the other group received unspaced text. All participants read unspaced text in the test phase. They found that children and adults spent less time reading and learning novel words in a spaced format than in an unspaced format, indicating that spacing facilitates the process of Chinese lexical acquisition. Furthermore, this facilitation of spacing
3
to word learning was maintained for children, but not for adults, during the subsequent test phase where all participants were reading unspaced text. This indicated that word spacing had a greater beneficial effect for children than for adults. Taken together, the results from these two studies show that word spacing is beneficial for children both when they are learning to read new Chinese words and also when they are reading words that they already know. In contrast, the reduced benefit of word spacing for adult readers suggests that they make use of other, linguistic cues within the sentences in order to segment and learn new words. One such source of linguistic information is the positional frequencies of a word’s constituent characters (see Liang et al., 2014; Yen et al., 2012). A character’s positional frequency refers to the frequency with which it appears in a particular location within a multicharacter word. Note that the majority of Chinese words are two characters long. Do readers use these positional frequencies as cues for the likelihood that a given character is at the beginning or end of a word? Although more than 80% of Chinese characters do not categorically demark word boundaries (see Yen et al., 2012), some characters occur most frequently at the beginning of words whilst others occur most frequently at the end of words. Yen et al. (2012) investigated whether these positional frequencies were used by Chinese readers as a word boundary cue. Sentences were constructed that contained a sequence of target characters which were ambiguous in that there were two possible locations for the word boundary that would have formed real words (though only one segmentation was correct within the particular sentence context). The boundary paradigm (Rayner, 1975) was used to examine whether or not the readers’ processing of these overlapping words was modulated by the positional probability of their constituent characters. The results showed a cost to processing when the positional frequencies of the target characters were incongruent with the segmentation of the words within the sentence frame. Yen et al. (2012) argued, therefore, that a character’s positional frequency was an effective linguistic word boundary cue that helped readers segment and identify words proficiently during Chinese reading. More recently, Liang et al. (2014) directly compared the contributions of word spacing and positional character frequency on the process of lexical acquisition for Chinese adult readers. With
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
4
LIANG ET AL.
respect to the manipulation of positional character frequency, three types of two-character pseudowords were constructed that provided either congruent, incongruent or no word boundary information. Each pseudoword was embedded in two sets of sentences (one set for the learning phase and another set for the test phase). With respect to the manipulation of word spacing, one group of participants read spaced text in the learning phase whilst the other group read unspaced text; all participants read unspaced text at test. The data showed a benefit of word spacing only in the learning phase and not in the test phase. On this basis, Liang et al. argued that word spacing appeared to facilitate the earliest stage of lexical acquisition—the triggering process. A facilitatory influence of positional character frequency was also observed, both in the learning and test phases. Specifically, reading times were shorter on congruent pseudowords and longer on incongruent pseudowords. Critically, there was no interactive effect between word spacing and character position probability, indicating that these two cues affected lexical acquisition independently. The authors argued that positional character frequency was likely to be primarily affecting the process of configuration during lexical acquisition, due to the fact that congruent and incongruent pseudowords are more or less word-like resulting from the pseudowords having more or fewer positionspecific neighbours. In alphabetic languages, the orthographic neighbourhood size of a word refers to the number of other words which differ from that word by a single letter (e.g., late, gate and rate are all neighbours; see Davis & Taft, 2005; Paterson, Liversedge, & Davis, 2009; Perea & Pollatsek, 1998; Pollatsek, Perea, & Binder, 1999). With respect to Chinese, it is more complex to define the orthographic neighbourhood: some researchers consider it to be those words which vary by a character (e.g., Huang et al., 2006; Tsai, Lee, Lin, Tzeng, & Hung, 2006), whilst other studies have defined it as those words which vary by a stroke (e.g., Wang, Tian, Han, Liversedge, & Paterson, 2014). In Liang et al.’s study (2014), they refer to the characterbased definition of orthographic neighbourhood size given the manipulation of constituent characters’ positional frequencies: if the initial character of two-character words frequently occurs at the beginning of two-character words then consequently it will have a large number of orthographic neighbours. Accordingly, Liang et al. found that within their stimuli, the orthographic
neighbourhood size for congruent pseudowords was larger than that for incongruent pseudowords. They argued, therefore, that neighbourhood size might underlie the effects associated with the manipulation of positional frequencies in their study. Although Yen et al.’s and Liang et al.’s studies have concerned the role of positional character frequency in Chinese lexical identification and acquisition; it is worth noting here that they both focus on Chinese adult reader. Children have lower reading skills than adults and, given this, we wished to examine whether or not children also use positional character information during the identification and acquisition of lexical representations. Furthermore, we wished to examine how such effects, were they observed, might interact (or not) with effects of word spacing in children. The present study used the same experimental paradigm as Liang et al. (2014), to extend existing findings and investigate such effects in relatively young child readers. First, we predicted that a benefit from word spacing would occur in the learning phase, with children in the spaced learning group having shorter reading times and making fewer fixations on the novel words as compared to those reading text in the unspaced format in the learning phase. With respect to the test phase, there were two possible outcomes. One possibility was that, as per Blythe et al. (2012), the advantage to reading times from word spacing would be maintained in the test phase (where all children were presented with traditional, unspaced text). The other possibility was that the benefit would not be maintained at test. This latter possibility was supported by the fact that skilled adult readers do not maintain a benefit at test (Blythe et al., 2012; Liang et al., 2014), and the present sample of child participants were a year older (e.g., had an additional year’s reading skill) than those in the sample reported by Blythe et al. (2012). Second, there were several factors that we considered might mediate the effects of positional character frequency in children. Note that such effects are inherently linked to reading experience as such probabilities can only be learned over time and with cumulative experience of processing such characters within printed text. Overall, we predicted that these children (who had at least three years formal experience of Chinese reading) would be sensitive to positional character information to some extent, at least. That is, we would find children’s reading times on
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
the novel words to be longest in the incongruent condition and shortest in the congruent condition. This prediction was qualified, however, by the fact that three years of formal literacy instruction does not mean that these children were skilled readers; rather, children at such a stage in their education are clearly still beginning readers. Given the dependence of positional character frequency upon experience, we anticipated that such effects would, therefore, be reduced relative to the effects seen in adults. Third, with respect to an interaction between the spacing and positional frequency manipulations, and based on the data from adults showing that these two effects were independent and affected different aspects of lexical acquisition (Liang et al., 2014), we predicted that children would also show no interactive effects of word spacing and positional frequencies.
METHOD Participants Forty-eight child participants who were in the third grade from Jinnan Experimental Primary School, with a mean age of 9.1 years (range = 8– 10 years), took part in the experiment. All participants had normal or corrected-to-normal vision and were naive regarding the purpose of the study.
Materials and design The stimuli used in this experiment were the same as those used in the study reported by Liang et al. (2014). The probability of each character’s withinword position was calculated as the number of words which contained that character as a twocharacter word beginning, or a two-character word ending character, divided by the total number of two-character words that contained the character (frequency data obtained from the SUBTLEX-CH corpus; Cai & Brysbaert, 2010). Three groups of characters (each group containing 20 characters) were selected: (1) characters that were frequently used as word beginnings (the mean probability of the characters as word beginning was 94%, ranging from 90% to 98%), where the mean number of words with those characters at their beginning was 54, and this was at least eight times more than the total number of words containing that
5
character as a word ending character (M = 4); (2) characters that were frequently used as word endings (the mean probability of the characters being used as word end character was 95%, ranging from 90% to 100%), where the number of words containing the character as a word ending (M = 75) was at least 10 times more than the total number of words containing the same character as word beginning (M = 5); (3) characters with equal probability of occurring at word beginnings and word endings (the mean probability as word beginning was 50%, with the range from 46% to 53% and the mean probability as word ending was 50%, ranging from 47% to 54%). The number of strokes (ranging from 3 to 10), character frequency (higher than 100 per million) and the productivity of two-, three-, and fourcharacter words were matched (see Table 1). There were no significant differences among these three groups of characters on these dimensions, all Fs < 2.0, all ps > .05. Three groups of two-character pseudowords were constructed (each finally containing 10 target pseudowords) on the basis of the constituent characters: (1) congruent pseudowords were made up of an initial character C1 with high word-beginning frequency and a final character C2 with high word-ending frequency; (2) incongruent pseudowords were comprised of C1 with high word-ending frequency and C2 with high word-beginning frequency; (3) balanced pseudowords were comprised of C1 and C2 that could appear in either position with equal likelihood (about 50%). In the first instance, 40 candidate pseudowords were created (30 were included in
TABLE 1 Example and properties of the selected characters Character type
Example Pinyin Mean character frequency (per million) Mean numbers of strokes Mean two-character productivity Mean three-character productivity Mean four-character productivity
Word beginning
Word ending
Both
右 you4 529
价 Jia4 539
夜 ye4 520
6.7 52
7.1 77
6.9 93
51
58
81
35
31
36
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
6
LIANG ET AL.
the final set of experimental stimuli). To ensure that the pseudowords were genuinely novel, and would not mistakenly be associated with any real word, we ensured that they did not appear in the Contemporary Chinese Dictionary (2005). Also, in order to make sure the pinyin (the phonological information associated with each character) of each pseudoword never resembled that of a real word, a list of the pinyin for 40 candidate pseudowords and their tones, as well as 20 filler words, (written using the Roman alphabet) were presented on paper. Fifteen undergraduates were presented with the pinyin for each pair of characters that comprised the candidate set of pseudowords, and were asked to write down pairs of characters that they considered were consistent with the pinyin and that formed real words (or to leave a blank space if they were unable to think of any characters that would fit). With the goal of ensuring that the pseudoword stimuli would not be mistaken for real words (on the basis of their phonological forms), these data were used to select pseudowords for which the participants were unable to complete the task. On the basis of the data from all these pre-screening procedures, a final set of 30 pseudowords was selected (10 congruent pseudowords, 10 incongruent pseudowords and 10 balanced pseudowords; see Table 2). Each target character only appeared once in all of the target words. There were no significant differences among the final three groups of pseudowords in total character frequencies or the total numbers of strokes, both Fs < 2.0, both ps > .05. The position-specific neighbourhood sizes for congruent and balanced pseudowords were significantly larger than that for incongruent pseudowords (both ts > 3, both ps < .01), but there was no significant difference
TABLE 2 Examples and properties of the three types of pseudoword Pseudoword type
Pseudoword Mean number of strokes/word Mean number of position-specific neighbours Mean summed character frequencies
Congruent
Balanced
Incongruent
右究 14.2
价抓 13.7
夜纸 13.9
86.1
92.9
11.8
2165
1470
1635
between congruent and balanced conditions, t(18) = 0.29, p > .05).1 Every target word was embedded into six sentence frames, each of which provided a context describing a plausible meaning of the pseudoword it contained. Each pseudoword was assigned to one of 10 real-world semantic categories (e.g., “右究” was designated as a kind of fruit which does not exist in the real world). Each category included three pseudowords, one in each of the positional frequency conditions (e.g., the category of fruit contained three pseudowords: “右究” was in the congruent condition, “价抓” was in the incongruent condition and “夜纸” was in the balanced condition). In total, there were three lists of stimuli of 180 experimental sentences associated with the 30 pseudowords, each consisting of 30 sets of three learning phase sentences and 30 sets of three test phase sentences. Each participant was presented with one list. Thus, every participant read every pseudoword, but the sentence frames were counterbalanced between participants (within the sets of three associated with each target word) so that they only read each sentence frame once. The target words never appeared at the very beginning or end of the sentences. The mean length of the sentences was 13.5 characters (ranging from 13 to 14 characters), which equalled 8 words on average (ranging from 6 to 10 words). 1 Whilst there is a strong association between positional probabilities and orthographic neighbours, these two variables are still distinct. For example, for a given character within a pseudoword, there might be 100 two-character words that are orthographic neighbours, within which 90 contain this character in the initial position and 10 contain this character in the end position. Thus, the positional probability of this particular character in the first position within a two-character word is 90%. For a different character within a pseudoword, there might be 180 twocharacter words that are orthographic neighbours, within which 90 contain this character in the initial position and 90 contain this character in the end position. Thus, the positional probability of this character in the first position within a two-character word is 50%. Given the positional probabilities of these two characters, we would have designated the first as a word-initial character for a pseudoword in the congruent condition and the second as a character in either position for a pseudoword in the balanced condition. This example demonstrates that although they have different positional probabilities, they can still have the same number of orthographic neighbours. Previous studies have shown that neighbourhood size has an effect on vocabulary acquisition (e.g., Hoover et al., 2010); however, the present study was not designed to disentangle the relative contributions of neighbourhood size and positional frequency.
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
A number of further pre-screens were conducted to examine some key characteristics of the sentences (in addition to those pre-screens that concerned the target words). First, the naturalness of the sentences was rated by a group of 15 undergraduates using a 5-point scale (a score of “1” meant the sentence was very unnatural, whereas a score of “5” meant the sentence was very natural).2 The average rating was 4.46 (SD = 0.16), indicating that the sentences constructed for the experiment were very natural. Second, the difficulty of the sentences was rated by 15 children (age-matched to those who took part in the main eye movement experiment) using a 5-point scale (a score of “1” meant the sentence was very difficult to understand, and a score of “5” meant the sentence was very easy to understand). The average difficulty rating was 3.8 (SD = 0.32), indicating that the sentences were suitable for child participants to read. Finally, the locations of word boundaries were also examined for consistency (note that in some cases there can be variation between Chinese readers with respect to their identification of the locations of word boundaries). Another 15 undergraduates were required to judge whether or not they agreed with the experimenters’ segmentation of the sentences. They were required to mark corrections wherever necessary. The mean agreement was 98.9% (SD = 1.3%), ranging from 94% to 100%. In order to ensure that participants were reading for meaning, both in the learning and test phases, a yes/no comprehension question followed one of the three sentence frames associated with each target word. Additionally, in order to test whether or not readers had learned the semantic category of each pseudoword after reading it within six sentential contexts, a multiple choice semantic category question (presenting 10 categories, of which 5 were used in the experiment and 5 were distractors) was presented to the participants. In total, there were 10 semantic categories which were used in the experiment (fruit, animal, clothes, container, architecture, medicine, vehicle, 2
When the naturalness and the difficulty of the sentences were evaluated by participants, the pseudowords were replaced by a real word which belonged to same semantic category, in order to remove the “weirdness” of the pseudoword itself (given that the goal was to assess the sentence frames, and not the target pseudowords). For example, when the pseudoword “挑尔” was designated to be a kind of fruit, it was replaced by “苹果” (apple) when the six sentence frames which contained “挑尔” were evaluated.
7
game, career and flower) and another 10 semantic distracters (weather, furniture, bank, beer, title, diploma, season, electrical equipment, book and colour). The probability of each category appearing in all the answers was equal. In the learning phase, there were two presentation conditions: normal, unspaced format and word spaced format. The participants were separated into two learning groups, and these two groups were matched on the following points: (1) gender, such that each group contained 12 boys and 12 girls; (2) mean age (t1(22) = 0.12, p > .05); (3) Chinese language ability, assessed by their scores on the most recent final-term examination, which was taken less than two months before they took part in the eye movement experiment (t1(22) = 0.45, p > .05). Half the participants read their set of sentences in normal, unspaced format, and half read the same set but in word-spaced format. In the test phase, all participants read another set of sentences in normal, unspaced format. The three sentences for each target word were blocked together, as shown in Table 3. A practice item was presented before the experimental sentences to ensure that participants were familiar with the experimental procedure.
Apparatus Participants’ eye movements from the right eye were recorded using a SR Research EyeLink 1000 eye tracker (sampling rate = 1000 Hz). The data were recorded with a sample rate of 1000 Hz, and the resolution of the monitor was 1024 × 768 pixels. Sentences were presented on a 19-inch DELL monitor at a viewing distance of 75 cm. Sentences were presented in black, Song font size 18 on a white background. Each character subtended 0.74°.
Procedure Each participant was tested individually. A chin rest was employed in order to minimise head movements. Prior to the start of the experiment, a horizontal three-point calibration procedure was completed (a maximum calibration error of less than 0.2° was accepted). After a successful calibration, sentences were presented in turn. Calibration was checked after each trial and recalibration was carried out during the experiment whenever necessary.
8
LIANG ET AL. TABLE 3 An example pseudoword in its six sentence frames, along with the related comprehension questions
Experiment phase
Sentence frame
Sentences with unspaced and spaced presentation conditions and translations
1
Unspaced: 成群的右究/价抓/夜纸生活在荒凉的沙漠中。 Spaced: 成群 的 右究/价抓/夜纸 生活 在 荒凉 的 沙漠 中。 Translation: Groups of Youjiu/jiazhua/yezhi live wild in the desert. Unspaced: 体型偏小的右究/价抓/夜纸看起来像老鼠。 Spaced: 体型 偏小 的 右究/价抓/夜纸 看 起来 像 老鼠。 Translation: The Youjiu/jiazhua/yezhi has a little body and looks like a mouse. Unspaced: 刚出生的右究/价抓/夜纸靠妈妈的乳汁生存。 Spaced: 刚 出生 的 右究/价抓/夜纸 靠 妈妈 的 乳汁 生存。 Translation: The newborn Youjiu/jiazhua/yezhi survives by suckling from its mother. Unspaced: 锋利的牙齿是右究/价抓/夜纸捕猎的工具。 Translation: The Youjiu/jiazhua/yezhi’s uses its sharp teeth when hunting. Unspaced: 睡觉时右究/价抓/夜纸的耳朵处于警觉状态。 Translation: While sleeping the Youjiu/jiazhua/yezhi’s ears are still alert. Unspaced: 行动灵活的右究/价抓/夜纸奔跑速度非常快。 Translation: The agile Youjiu/jiazhua/yezhi runs very fast. 请问: 右究/价抓/夜纸属于以下哪个类别? (Question: Which category does Youjiu/jiazhua/yezhi belong to?) 职业(career) 动物(animal) 水果(fruit) 书本(book) 交通工具(vehicle) 电器(electric equipment) 家具(furniture) 酒类(wine) 衣服(clothes) 颜色(color)
Learning phase
2
3
Test phase
4
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
5 6 Multiple choice question
Here, the three possible two-character pseudowords for each sentence frame are shown as an example to demonstrate our counterbalancing procedure. Note that, within the eye movement experiment, only one pseudoword was presented within each sentence.
Participants were informed that there would be some words that they did not know within the sentences, and they were instructed to read the sentences normally and understand them to the best of their ability. Participants were instructed to click the mouse when they had finished reading each sentence. They were also informed that occasionally a comprehension question would appear, and they should try their best to answer the question correctly by clicking the corresponding answers (pre-defined regions of the screen) both in the learning and the test phases. The learning phase lasted approximately 50 minutes. There was a short rest (30 minutes) between these two experimental phases. The task in the test phase was the same as that in the learning phase, except for the additional inclusion of multiple choice semantic category questions that were also answered by clicking the mouse. In total, the test phase lasted about 60 minutes.
RESULTS The mean score on the comprehension questions was 76.9% in the learning phase (ranging from 60% to 93%) and 87.2% in the test phase (ranging from 60% to 100%), indicating the children understood the sentences even though each
sentence contained novel vocabulary. The mean score on the multiple choice semantic category questions in the test phase was 76.6%, suggesting that children were able to learn about the semantic category of the pseudowords after several exposures in different sentential contexts. In addition, the mean score on the multiple choice semantic category questions for the spaced learning group (80.6%) was significantly higher than those for the unspaced learning group (72.6%), t(23) = 2.20, p < .05, suggesting that word spacing helps Chinese child readers learn novel words more effectively, at least to some extent. With respect to the eye movement data, fixations shorter than 80 ms or longer than 1200 ms were excluded from the analyses. Two further criteria were also adopted for the exclusion of data: (1) trials on which tracker loss occurred, (2) trials containing fewer than four fixations. In total, 1.1% of the data was excluded. We report local analyses of eye movement behaviour on the target pseudoword in each sentence. We report first fixation duration (the duration of the first fixation on the target pseudoword), gaze duration (the sum of all first pass fixations made on the target pseudoword before the eyes moved to another word within the sentence) and total fixation time (the sum of all fixations on the pseudoword). The data were analysed using three-way
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
9
TABLE 4 The mean (standard deviation) of all the eye movement measures across the different experimental conditions Learning Measures
Pseudoword type
Unspaced
First fixation duration (ms)
Congruent Balanced Incongruent Congruent Balanced Incongruent Congruent Balanced Incongruent
296 300 310 547 494 557 1284 1198 1454
Gaze duration (ms)
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
Total fixation time (ms)
repeated-measures analyses of variance with Pseudoword Type (congruent vs. balanced vs. incongruent) and Experiment Phase (learning vs. test) as within-participant variables, and Learning Group (unspaced vs. spaced text) as a between-participant variable. The mean values for these local measures under each condition are given in Table 4. An effect of Experiment Phase was observed on first fixation duration that was marginal by participants and reliable by items, F1(1, 46) = 3.67, p = .06; F2(1, 27) = 5.92, p < .05. Children made longer first fixations on pseudowords in the learning phase than in the test phase. A similar pattern was also observed for gaze duration and total fixation time (all Fs > 50, all ps < .001), such that reading times were longer in the learning phase as compared to those in the test phase. Recall that the first three encounters with the pseudowords occurred in the learning phase, and the fourth to sixth encounters occurred in the test phase. Thus, these results likely indicate that the more often the children were exposed to the pseudowords, the more quickly they were able to process and lexically identify them. The main effect of Learning Group was marginally significant for first fixation duration, F1(1, 46) = 2.96, p = .09; F2(1, 27) = 23.87, p < .001, and was significant for gaze duration and total fixation time (all Fs > 4, all ps < .05). More importantly, this effect was qualified by an interaction between Learning Group and Experiment Phase. This interaction was reliable across all three measures (all Fs > 3.9, all ps < .05). The t-tests showed that children in the spaced learning group had shorter reading times than those in the unspaced learning group in the learning phase (all ts > 2.3, all ps < .05). There were no reliable differences between these two learning groups at test, where all children
(33) (45) (47) (125) (128) (127) (317) (312) (346)
Test Spaced 276 274 289 413 405 452 992 950 1090
(34) (38) (33) (82) (82) (82) (256) (167) (328)
Unspaced 283 288 287 409 430 437 816 835 930
(32) (37) (37) (75) (79) (95) (243) (216) (263)
Spaced 284 279 277 390 401 413 883 845 960
(41) (36) (30) (71) (79) (84) (263) (222) (248)
read the sentences in the unspaced format: first fixation duration (mean difference = 7 ms; t1(46) = 0.65, p > .05; t2(29) = 1.70, p > .05); gaze duration (mean difference = 24 ms; t1(46) = 1.12, p > .05; t2(29) = 3.30, p < .01); total fixation time (mean difference = −16 ms; t1(46) = 0.54, p > .05; t2(29) = 2.13, p < .05). Note that the magnitude of these differences was substantially less than the comparable effects that were observed in the learning phase (21 ms for first fixation duration, 107 ms for gaze duration and 296 ms for total fixation time). As indicated in the predictions, there was some uncertainty over whether or not the spacing effect we observed in the learning phase would carry over into the test phase, given the age of the child participants in the present study compared to the participants in the Blythe et al. (2012) study. These results suggest that the present sample of children did not maintain the benefit of word spacing learnt at test. To examine these effects of the learning group further, we conducted some additional t-tests to determine how each of the two groups differed in their reading behaviour between the learning and test phases. Children in the unspaced group had longer reading times on the pseudowords in the learning phase than in the test phase: first fixation duration (mean difference = 17 ms; t1(23) = 9.44, p < .001; t2(29) = 4.84, p < .001); gaze duration (mean difference = 107 ms; t1(23) = 2.85, p < .01; t2(29) = 11.83, p < .001); total fixation time (mean difference = 452 ms; t1(23) = 7.53, p < .001; t2(29) = 15.11, p < .001). In contrast, children in the spaced group did not show reliable differences in first fixation duration or gaze duration between the learning and test phase (first fixation duration: mean difference = 1 ms, t1(23) = 2.78, p < .05; t2(29) = 0.01, p > .05; gaze duration: mean
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
10
LIANG ET AL.
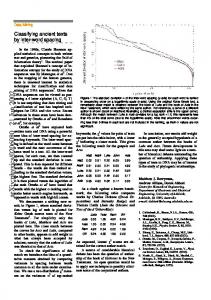
difference = 22 ms, t1(23) = 0.05, p > .05; t2(29) = 2.18, p < .05), although this difference was significant for total fixation times (mean difference = 115 ms, t1(23) = 2,14, p < .05; t2(29) = 5.92, p < .001). These analyses showed, therefore, that children in the unspaced learning group showed greater improvement between the learning and test phase than those in the spaced learning group. Finally, when considering the interaction between learning group and experiment phase, we examined total fixation times on the target words as a function of the sentence frames in which they appeared (three sentence frames per pseudoword in the learning phase and three in the test phase). The overall tendency was similar for the two learning groups: reading times on the pseudowords gradually reduced over repeated exposures within different sentential contexts (see Figure 1). Interestingly, and consistent with our analyses of the interaction showing that there was a benefit of word spacing in the learning phase that was not maintained at test, Figure 1 shows clearly that reading times increased between the last trial of the learning phase and the first trial of the test phase for children in the spaced group. Specifically, whilst their reading times gradually decreased within each separate phase of the experiment, there was a relatively sharp increase between the two phases (which did not occur for children in the unspaced group). It is likely that this can be attributed to the salient change in visual format that the children in the spaced learning group experienced—they read word spaced texts in the learning phase but unspaced text in the test phase, in contrast to the unspaced group for whom the visual format of the text was consistent throughout both phases of the experiment.
Figure 1. reading.
The main effect of Pseudoword Type was not significant for first fixation duration, F1(2, 92) = 1.67, p > .05; F2(2, 27) = 0.84, p > .05. In contrast, we found an effect of Pseudoword Type for gaze duration that was significant by subjects and marginal by items, F1(2, 92) = 11.72, p < .001; F2(2, 27) = 2.74, p = .08. Gaze durations were longer on incongruent pseudowords than either congruent (though this difference was marginal in the item-analyses, t1(47) = 3.57, p < .01; t2(18) = 1.69, p = .11) or balanced pseudowords, t1(47) = 4.43, p < .001; t2(18) = 2.38, p < .05. The difference between the congruent and balanced conditions was not reliable, t1(47) = 1.14, p > .05; t2(18) = 0.48, p > .05. Similar patterns were observed on total fixation time, F1(2, 92) = 33.06, p < .001; F2(2, 27) = 3.89, p < .05. Children spent longer reading incongruent pseudowords than pseudowords in the congruent or balanced conditions (all ts > 2.3, all ps < .05), but no reliable differences were found between the congruent and balanced pseudowords, t1(47) = 1.84, p > .05; t2(18) = 0.59, p > .05. Together, the gaze duration and total fixation time results indicated that, overall, when children learnt a novel pseudoword with constituent characters that appeared at locations in words that they did not usually occupy, then they experienced more processing difficulty than when the constituent characters appeared at locations in words that they did ordinarily occupy. This pattern of results is consistent with those for adults reported by Liang et al. (2014), suggesting that even though children have less reading experience than adults, they are still sensitive to positional character frequency information when they acquire novel lexical items. Alongside the main effect of Pseudoword Type, we observed a robust interaction between
Total reading times on the pseudowords across the six sentence frames per pseudoword during spaced and unspaced text
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
Pseudoword Type and Experiment Phase on all three reading time measures (all Fs > 3.1, all ps < .05). The t-tests were carried out to compare pairs of conditions in each phase separately. In the learning phase, these showed that first fixation durations were longer on incongruent pseudowords than either balanced, t1(47) = 2.50, p < .05; t2(18) = 2.05, p = .06, or congruent pseudowords, t1(47) = 2.53, p < .05; t2(18) = 1.59, p = .13, though note that the items analyses did not reach significance. The difference between the balanced and congruent pseudowords was, again, not significant, t1(47) = 0.24, p > .05; t2(18) = 0.13, p > .05. Thus, incongruent character positions increased reading times during the learning phase of the experiment. In contrast, there were no reliable differences between pseudoword types (all ts < 0.5, all ps > .05) in the test phase. These analyses show, therefore, that the disruption associated with incongruent positional character information, arguably indicative of probabilistic word boundary information, occurred in first fixation durations in the learning phase, but did not influence this very early lexical processing in the test phase. Gaze durations in the learning phase were numerically longer (25 ms) for incongruent pseudowords than for congruent pseudowords. Note, though, that this effect was only reliable across participants, t1(47) = 2.22, p < .05; t2(18) = 1.33, p = .20). The difference between the incongruent and balanced condition reached significance across both participants and items, mean = 54 ms; t1(47) = 5.31, p < .01; t2(18) = 3.18, p < .01. There was a slightly surprising difference of 29 ms between the congruent and balanced conditions, but this effect was far from significant across items, t1(47) = 2.49, p < .05; t2(18) = 1.64, p > .05. In the test phase, we observed one marginally reliable effect which occurred between the incongruent and balanced conditions, the effect was 25 ms, t1(47) = 2.68, p < .05; t2(18) = 1.81, p = .09, whilst all other effects were not reliable (all ts < 2, ps > .05). Overall, when the t-test results for gaze duration were noisy in terms of significance, the pattern of effects was consistent with that observed in first fixation duration; specifically, incongruent pseudowords received longer gaze durations than pseudowords in the other two conditions, but the magnitude of this effect was much reduced in the test phase as compared to the learning phase. Finally, for total fixation time, the t-test results showed that incongruent pseudowords received longer reading times than congruent pseudowords in the learning phase and the test phase, learning
11
phase: t1(47) = 4.75, p < .001; t2(18) = 1.79, p = .09; test phase: t1(47) = 4.54, p < .001; t2(18) = 2.89, p < .05, although, once again, the effect was marginal in the items analysis in the learning phase. Incongruent pseudowords had longer total reading times than balanced pseudowords in both the learning and test phases (all ts > 2.3, all ps < .05). Again, the magnitude of the difference in the learning phase (193 ms) was greater than that in the test phase (109 ms). Finally, we did not find robust differences between congruent and balanced pseudowords for total reading time in either the learning, t1(47) = 2.35, p < .05; t2(18) = 0.82, p > .05, or the test phase, t1(47) = 0.41, p > .05; t2(18) = 0.15, p > .05. Again, based on the analyses of total fixation time, we found a facilitatory effect of congruent positional character frequency across the entire experiment, but the extent of this effect was greatly reduced in the test phase. The two-way interaction between Pseudoword Type and Learning Group was not reliable for first fixation duration, gaze duration or total reading time (all Fs < 3, all ps > .05). Furthermore, all the three-way interactions were negligible on these three eye movement measures (all Fs < 2.6, all ps > .05).
DISCUSSION The current study was designed to examine the role of word spacing and positional character frequency on lexical acquisition by child readers. Both of these two segmentation cues were found to affect reading times on pseudowords. Strikingly, and consistent with adult data from previous studies, there was no eye movement evidence of an interaction with word spacing and positional character frequency, indicating that these two cues impacted on lexical acquisition independently. Each effect will be discussed in turn. The eye movement data showed clear differences between children learning novel words in unspaced text compared with those learning the words in spaced text. Reading times on the novel words were significantly reduced by inserting spaces between words in the learning phase. In contrast, however, this facilitation to lexical processing from word spacing was not maintained in the subsequent test phase, where all participants read unspaced text. Recall that in Blythe et al.’s study (2012), the benefit of word spacing was observed in both the learning and test phases
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
12
LIANG ET AL.
within the children’s data. As discussed in the Introduction, we consider it likely that the discrepancy between these two studies might be due to the fact that children in the present study (third grade, mean age of 9.1 years) were older than those in the Blythe et al. study (2012; second grade, mean age of 8.3 years). Supporting this argument further, the spacing effects within the present data-set were quite similar to those reported for skilled adult readers (Liang et al., 2014). The spacing effect in the learning phase was, however, of greater magnitude here for children compared to that reported for adults: for total fixation times, the effect was 296 ms for children and was only 63 ms for adults (Liang et al., 2014). We suggest that a reader’s ability to learn novel vocabulary when encountered during text increases in efficiency with age and reading skill. An informal comparison of the data from the three participant groups reported in the present manuscript, and by Blythe et al. (2012) and Liang et al. (2014), indicates that whilst readers of all ages process new words faster during their initial encounters if those words are presented in a spaced format, the extent to which this benefit persists over time and over subsequent encounters may decrease with age and reading skill. Children perform many of the linguistic operations that are required for comprehension less efficiently than do adults (Reichle et al., 2013) and, therefore, we suggest that children are more likely to depend on visual word segmentation cues when available. Once they become skilled readers, this greater proficiency allows them to identify word boundaries with greater ease through the use of linguistic cues within the text. With respect to the word spacing manipulation, this means that even though such salient and valid cues facilitate lexical processing, they become increasingly redundant as the reader’s age and skill increase. Interestingly, an inspection of the reading times in Table 3 shows that when children in the spaced learning group had relatively similar, and shorter, reading times in both the learning and test phases of the experiment, it was only the children in the unspaced group who showed a marked improvement in their reading times between these two experimental phases. One explanation for this pattern is that the data might be showing a floor effect (in terms of the lexical acquisition process) such that the presence of word spaces allowed children in the spaced group to learn these words as efficiently as was possible for them. Specifically, the presence of word spacing had a strong, and
immediate, benefit to word learning that persisted throughout the course of the experiment. In contrast, for the unspaced learning group, triggering and configuration were slower and/or less efficient than for the spaced learning group. The lack of spaces within the learning phase was, relatively, so detrimental that processing times on those pseudowords were very long and there was, therefore, plenty of scope within the experimental paradigm for us to observe an improvement to those children’s reading times between the learning and test phases. Where a benefit of word spacing was observed in the learning phase, it seems likely that it was associated with the very early components of lexical acquisition. In order to trigger the formation of a new lexical entry, a Chinese reader must identify which adjacent characters comprise the new word so that the mismatch with existing lexical entries can be accurately detected. Subsequently, consistent with models of spoken word learning, a configuration process should occur in which the newly triggered representation becomes more fully specified in terms of adding further orthographic, phonological and semantic information over subsequent encounters with the word (Leach & Samuel, 2007). We consider it likely that, within the learning phase, four repetitions of each pseudoword within different sentences frames were more than sufficient to complete the triggering process. It also seems likely, given that each participant completed both phases of the experiment within 24 hours, that the test phase was most relevant to additional configuration processing (the subsequent process of engagement seems to occur more slowly, over two to seven days; Gaskell & Dumay, 2003). Given our observation of effects of word spacing on first fixation durations, an early measure of lexical processing, within the learning phase only, we suggest that presence of word spaces might facilitate the triggering of a new lexical representation. When a novel word is encountered in traditional, unspaced Chinese text the reader must depend on the sentential context to determine how many and which adjacent characters comprised of a novel word. Only once the correct word segmentation occurs it is possible for readers to identify the mismatch between the current input and existing cognitive representations and, consequently, to trigger a new representation. The presence of word spacing provides readers with salient word boundary locations, thus allowing them to more
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
quickly and accurately determine which adjacent characters comprise the new word. Turning to the effect of positional character frequency, first of all, children had longer reading times on pseudowords providing incongruent cues than those in either the congruent or balanced conditions. Strikingly, this result was consistent with that reported by Liang et al. (2014) suggesting that, similar to adult readers, children from the age of eight years are sensitive to positional frequency information when learning novel words within sentences. Specifically, this result indicates that from a relatively young age and with just a few years of reading experience, children’s lexical processing becomes sensitive to positional frequencies, and combinatorial probabilities, for characters. Again consistent with the data reported by Liang et al., reading times on the pseudowords did not significantly differ between the congruent and balanced conditions. Interestingly, there were no significant interactions between the manipulations of positional character frequency and word spacing. This was consistent with the pattern of Chinese adults’ data reported by Liang et al. (2014), suggesting that word spacing and positional frequencies affect lexical acquisition independently. In contrast, these results differ from those reported for Japanese reading. Sainio, Hyönä, Bingushi, and Bertram (2007) found that word spacing facilitated word identification when reading pure Hiragana (syllabic) script, but not when reading the mixed Kanji-Kana script that contained ideographic characters. They argued that the visually salient Kanji characters might serve as a strong word segmentation cue, allowing Japanese readers to find word boundaries efficiently. Consistent with this, they found that word spacing seemed to be unnecessary for readers as an additional visual word boundary cue. However, the results in the present study showed that irrespective of the presence or absence of word spacing, the same pattern of effects was observed with respect to readers’ processing of incongruent, congruent and balanced pseudowords. This suggests that these two cues affected the process of lexical acquisition independently, strongly implicating that processing of positional character frequencies influences some aspect of lexical acquisition beyond the basic identification of word boundaries (e.g., Liang et al., 2014). We will return to this point later. A likely explanation for the effect of positional character frequency is associated with the orthographic neighbourhood size of the target words.
13
By definition, the pseudowords containing characters with high positional frequencies will have a large number of orthographic neighbours (those words which share all but one, position-specific characters)—it is due to this large cohort of neighbours that the reader has learned that the constituent characters are likely to fall in their particular word-beginning or word-ending positions. In contrast, again by definition, those pseudowords containing characters with low positional frequencies will have few orthographic neighbours because those characters rarely appear in the specified positions within words. Recall that, the neighbourhood size for congruent and balanced pseudowords in the present stimuli was significantly larger than those for incongruent pseudowords, but there was no significant difference between congruent and balanced conditions. And within the main effect of positional character frequency within the eye movement data, t-tests showed that it was the incongruent condition that resulted in longer reading times whilst the congruent and balanced conditions were not reliably different. The patterns within the data matched closely, therefore, with the differences between conditions in orthographic neighbourhood size. On this basis, it seems likely that the inhibitory influence of incongruent positional character frequencies is associated with the low neighbourhood size for these pseudowords. Pseudowords with more orthographic neighbours are more wordlike than those with fewer neighbours (Andrews, 1989, 1992), and previous studies have shown that neighbourhood size affected all three components of lexical acquisition for child readers (Hoover et al., 2010). Note that the present study does not allow us to disentangle the contributions of these two variables—characters’ positional frequencies and word neighbourhood sizes—and this seems to be a promising issue for future research to investigate. Importantly, however, this result suggests sensitivity to the probability with which characters appear within particular locations and/or in particular character combinations within words in relatively young beginning readers, such that it influences the ease of lexical processing. Alongside these striking similarities between children and adults in terms of the effect of positional character frequency, there was one clear difference: the interaction between Pseudoword Type and Experiment Phase was significant for children on all of the three reading time measures, but this interaction was not significant in the data reported for adult readers by Liang et al. (2014).
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
14
LIANG ET AL.
In the present data-set from child readers, there were longer reading times on incongruent pseudowords than on congruent or balanced pseudowords in both the learning and test phases, but the magnitude of this effect was substantially reduced at test. Recall that the learning phase is likely to have allowed the reader to complete the triggering process and also to begin the configuration process within lexical acquisition, whilst the test phase would have allowed the reader to continue configuration. We suggest, therefore, that the effect of the positional frequency manipulation in both experiment phases indicates that increased neighbourhood size is beneficial to both the triggering and configuration processes in lexical acquisition. Furthermore, this is consistent with data from studies of children’s spoken word acquisition (see Hoover et al., 2010), where neighbourhood size affected both these aspects of lexical acquisition. Given the stronger effect of positional character frequency in the learning phase we suggest that, for child readers, wordlikeness is particularly influential on the process of triggering the formation of a novel lexical entry. That is, children notice quickly whether or not the positions of characters match up to what they are already familiar with in terms of where characters typically appear within words, and strong discrepancies with their previous experience speed up the triggering process. Although this word-likeness (as indexed by orthographic neighbourhood size) also affects the slightly later configuration process, its influence there seems to be reduced relative to the early influence on triggering. In summary, the present experiment showed that, despite its dependence upon reading experience, positional character frequency affects lexical acquisition in beginning readers from the age of nine years. Furthermore, processing of word spacing is independent from processing of positional character frequency in child readers, as has previously been shown to be the case for skilled adult readers. The insertion of word spacing provides clear demarcation of word boundaries, allowing the child readers to quickly and accurately determine which constituent characters comprised the novel words. This allows quick detection of the mismatch between the novel orthographic input and existing lexical representations, thus, facilitating a very early aspect of lexical acquisition—the triggering component. The positional frequency of characters within a word is strongly associated with neighbourhood size, and affected both the
triggering and the configuration components of lexical acquisition.
REFERENCES Andrews, S. (1989). Frequency and neighborhood effects on lexical access: Activation or search? Journal of Experimental Psychology: Learning, Memory, and Cognition, 15, 802–814. Andrews, S. (1992). Frequency and neighborhood effects on lexical access: Lexical similarity or orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 234–254. Bai, X., Yan, G., Liversedge, S. P., Zang, C., & Rayner, K. (2008). Reading spaced and unspaced Chinese text: Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 34, 1277–1287. doi:10.1037/0096-1523. 34.5.1277 Blythe, H. I., & Joseph, H. S. S. L. (2011). Children’s eye movements during reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Oxford handbook on eye movements (pp. 643–662). Oxford: Oxford University Press. Blythe, H. I., Liang, F., Zang, C., Wang, J., Yan, G., Bai, X., & Liversedge, S. P. (2012). Inserting spaces into Chinese text helps readers to learn new words: An eye movement study. Journal of Memory and Language, 67, 241–254. doi:10.1016/j.jml.2012.05.004 Cai, Q., & Brysbaert, M. (2010). SUBTLEX-CH: Chinese word and character frequencies based on film subtitles. PLoS ONE, 5, 1–8. Capone, N. C., & McGregor, K. K. (2005). The effect of semantic representation on toddler’s word retrieval. Journal of Speech, Language, and Hearing Research, 48, 1468–1480. doi:10.1044/1092-4388(2005/102) Carpenter, G. A., & Grossberg, S. (1987). A massively parallel architecture for a self-organizing neural pattern recognition machine. Computer Vision, Graphics, and Image Processing, 37, 54–115. Contemporary Chinese Dictionary. (2005). Beijing: Commercial Publishing House. Davis, C. J., & Taft, M. (2005). More words in the neighborhood: Interference in lexical decision due to deletion neighbors. Psychonomic Bulletin and Review, 12, 904–910. doi:10.3758/BF03196784 Gaskell, M. G., & Dumay, N. (2003). Lexical competition and the acquisition of novel words. Cognition, 89, 105–132. Gershkoff-Stowe, L. (2002). Object naming, vocabulary growth, and the development of word retrieval abilities. Journal of Memory and Language, 46, 665– 687. doi:10.1006/jmla.2001.2830 Gupta, P., & MacWhinney, B. (1997). Vocabulary acquisition and verbal short-term memory: Computational and neural bases. Brain and Language. Special Issue: Computer Models of Impaired Language, 59, 267–333. Hoover, J. R., Storkel, H. L., & Hogan, T. P. (2010). A cross-sectional comparison of the effects of phonotactic probability and neighborhood density on word learning by preschool children. Journal of
Downloaded by [Winchester School of Art] at 01:51 19 May 2015
CHILDREN’S USAGE OF WORD SEGMENTATION CUES
Memory and Language, 63(1), 100–116. doi:10.1016/j. jml.2010.02.003 Huang, H.-W., Lee, C.-Y, Tsai, J.-L., Lee, C.-L., Hung, D. L., & Tzeng, O. J.-L. (2006). Orthographic neighborhood effects in reading Chinese two-character words. Cognitive Neuroscience and Neuropsychology, 17, 1061–1065. Leach, L., & Samuel, A. G. (2007). Lexical configuration and lexical engagement: When adults learn new words. Cognitive Psychology, 55, 306–353. doi:10.10 16/j.cogpsych.2007.01.001 Li, X., Rayner, K., & Cave, K. R. (2009). On the segmentation of Chinese words during reading. Cognitive Psychology, 58, 525–552. doi:10.1016/j.cogp sych.2009.02.003 Liang, F., Blythe, H. I., Bai, X., Yan, G., Li, X., Zang, C., & Liversedge, S. P. (2014). Different roles of word spacing and positional character frequency on Chinese word learning during natural reading task: An eye movement study. Journal of Memory and Language, in revision. Morris, R. K., Rayner, K., & Pollatsek, A. (1990). Eye movement guidance in reading: The role of parafovel letter and space information. Journal of Experimental Psychology: Human Perception and Performance, 16, 268–281. doi:10.1037/0096-1523.16.2.268 Paterson, K. B., Liversedge, S. P., & Davis, C. J. (2009). Inhibitory neighbor priming effects in eye movements during reading. Psychonomic Bulletin & Review, 16(1), 43–50. doi:10.3758/PBR.16.1.43 Perea, M., & Acha, J. (2009). Space information is important for reading. Vision Research, 49, 1994– 2000. doi:10.1016/j.visres.2009.05.009 Perea, M., & Pollatsek, A. (1998). The effects of neighborhood frequency in reading and lexical decision. Journal of Experimental Psychology: Human Perception and Performance, 24, 767–779. doi:10.1037/0096-1523.24.3.767 Pollatsek, A., Perea, M., & Binder, K. S. (1999). The effects of “neighborhood size” in reading and lexical decision. Journal of Experimental Psychology: Human Perception and Performance, 25, 1142–1158. doi:10.1037/0096-1523.25.4.1142 Pollatsek, A., & Rayner, K. (1982). Eye movement control in reading: The role of word boundaries. Journal of Experimental Psychology: Human Perception and Performance, 8, 817–833. doi:10.1037/00961523.8.6.817 Rayner, K. (1975). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7(1), 65–81. doi:10.1016/0010-0285(75)90005-5 Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422. doi:10.1037/00332909.124.3.372 Rayner, K., Fischer, M. H., & Pollatsek, A. (1998). Unspaced text interferes with both word
15
identification and eye movement control. Vision Research, 38, 1129–1144. doi:10.1016/S0042-6989(97) 00274-5 Reichle, E. D., Liversedge, S. P., Drieghe, D., Blythe, H. I., Joseph, H. S. S. L., White, S. J., & Rayner, K. (2013). Using E-Z reader to examine the concurrent development of eye-movement control and reading skill. Developmental Review, 33, 110–149. doi:10.10 16/j.dr.2013.03.001 Sainio, M., Hyönä, J., Bingushi, K., & Bertram, R. (2007). The role of interword spacing in reading Japanese: An eye movement study. Vision Research, 47, 2575–2584. doi:10.1016/j.visres.2007.05.017 Shen, D., Liversedge, S. P., Tian, J., Zang, C., Cui, L., Bai, X., … Rayner, K. (2012). Eye movements of second language learners when reading spaced and unspaced Chinese text. Journal of Experimental Psychology: Applied, 18, 192–202. doi:10.1037/ a0027485 Storkel, H. L., Armbrüster, J., & Hogan, T. P. (2006). Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech, Language, and Hearing Research, 49, 1175–1192. Storkel, H. L., & Lee, S.-Y. (2011). The independent effects of phonotactic probability and neighborhood density on lexical acquisition by preschool children. Language and Cognitive Processes, 26, 191–211. Tsai, J.-L., Lee, C.-Y., Lin, Y.-C., Tzeng, O.-L., & Hung, D. L. (2006). Neighborhood size effects of Chinese words in lexical decision and reading. Language and Linguistics, 7, 659–675. Wang, J. X., Tian, J., Han, W. J., Liversedge, S. P., & Paterson, K. B. (2014). Inhibitory stroke neighbor priming in character recognition and reading in Chinese. The Quarterly Journal of Experimental Psychology, 67, 2149–2171. Wu, J., Slattery, T. J., Pollatsek, A., & Rayner, K. (2008). Word segmentation in Chinese reading. In K. Rayner, D. Shen, X. Bai, & G. Yan (Eds.), Cognitive and cultural influences on eye movements (pp. 303–314). Tianjin: Tianjin People Press; Psychology Press. Yen, M.-H., Radach, R., Tzeng, O. J.-L., & Tsai, J.-L. (2012). Usage of statistical cues for word boundary in reading Chinese sentences. Reading and Writing, 25, 1007–1029. Zang, C., Liang, F., Bai, X., Yan, G., & Liversedge, S. P. (2013). Interword spacing and landing position effects during Chinese reading in children and adults. Journal of Experimental Psychology: Human Perception and Performance, 39, 720–734. doi:10.1037/ a0030097 Zang, C., Liversedge, S. P., Bai, X., & Yan, G. (2011). Eye movements during Chinese reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), The Oxford handbook of eye movements (pp. 961–978). Oxford: Oxford University Press.