6 Feb 2015 - M. Lopez-Cruz et al. 1 SI. Supporting Information for: Increased prediction accuracy in wheat breeding lines using a marker × environment ...
Jun 8, 2011 - Instituto de Matemática, UFRGS â Avenida Bento Gonçalves, 9500, ... Instituto de Matemática e Estatıstica, USP â Rua do MatËao 1010, ...
SPARC smaple 1 a. 3.946787 2.299416 0.511379. 4.710001 0.808495 0.767076 smaple 1 b. 3.946787 2.299416 0.511379. 4.710001 0.808495 0.767076.
Egleston CV, Ben Aslam H, Lambert MA. Capnography for monitoring non-intubated spontaneously breathing patients in an emergency room setting. J Accid ...
TPChic0613. SufD protein. FeS assembly. TPChic0079. Putative aldehyde oxidase and xanthine dehydrogenase family protein. Oxidative metabolism of purines.
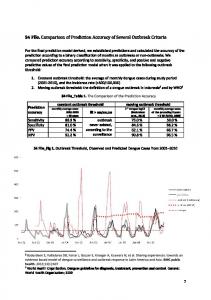
(2001-2010), and the incidence rate (>300/100,000). 2. Moving ... Jan-01 Jan-02 Jan-03 Jan-04 Jan-05 Jan-06 Jan-07 Jan-08 Jan-09 Jan-10. 2 Badurdeen S ...
Kujyana umwana cg abana banyu ku kigo nderabuzima mu gihe arwaye cyangwa kumukingiza. Question relevant when: ${A. 16} !='0'. 1. Burigihe ni wowe.
Child-Staff Ratios in Early Childhood Education and Care Settings and Child. Outcomes: ... Child-Staff Ratio Quality Indicator: List of Child Outcome Variables.
S4 File. Additional results experiment 3. Mimicry effect, response facilitation and ... group) and THREAT (Happy, Angry/No Personal Threat, Angry/Personal ...
Interestingly, the basic brute force approach that gives the exact solution to this problem is highly parallelizable as the nearest neighbours of each query point ...
S4 File. - PLOS › 325411171_S4_File › data › 325411171_S4_File › datagot emotional feelings which were: 0 Very weak or ... O Moderately emotionally distant from my baby ... this baby and how you feel about being a mother. 2. 3.
main text, depends on the exponent γi through the vector of energies ei = |yi|γi ... Regarding the second term in Eq. S4.2, âγi ei, by taking element-wise ...
S4 File. MIMS sample preparation. A 300 mL sample of culture was placed in a large gas tight syringe and gently bubbled with N2 gas for ~ 20 minutes to lower ...
Prдzisions-Gewindelehren. Metrisches ISO-Gewinde DIN 13. LehrenmaЯe nach
DIN ISO 1502. Precision thread gauges. ISO metric thread DIN 13.
Page 1. Figure S5. A. LD mt. LD mt. B.
Brijendra Kumar Joshi, Data Structures and Algorithms in C, McGraw Hill , New ...
Sudipta Mukherjee, , Data Structures using C 1000 Problems and Solutions, ...
ÎAFIs yield inflated errors in smaller samples. Permuting the maximum modification index among equality constraints control familywise Type I error rates when ...
Sep 28, 2014 - regarded as a (transitive) permutation group on the roots Xl, ... , Xn. (and so having degree n). Then A is called the arithmetic monodromy group ...
of genes, genetic variants and chemicals respectively. These three services ... Department of Integrative Structural and Computational Biology, The Scripps. Research Institute, La Jolla, CA, ..... Monarch Initiative [26], CEDAR [28], and UniProt [29]
LD EVALUATION THROUGH PERMUTATION IN DISCOVERY AND VALIDATION #1. DATASETS. We want to estimate the null distribution of the number of ...
S4 File: LD EVALUATION THROUGH PERMUTATION IN DISCOVERY AND VALIDATION #1 DATASETS
We want to estimate the null distribution of the number of SNPs for which D’=1 in the region without assuming independence of the SNPs. We generated 200 replicate permutations for each group (stages I/II and IV) to obtain the null distributions. For each individual and each SNP, separately, we permuted the genotype. The permutations were performed as follows:
The minor allele frequencies were kept exactly the same as in the original data. Missing genotypes were allowed and randomized as genotypes in the permutations. D’ between rs60745952 and each of the other SNPs was calculated.
We then counted, for each permutation, the number of SNPs in the region for which D’=1 to obtain the empirical null distribution for the number of SNPs in the region for which D’=1. The empirical null distributions for Stage I/II and Stage IV in the discovery and validation datasets are shown below as histograms:
Frequency distribution of the number of SNPs with D’=1 relative to rs60745952 as determined in 200 permutations of stage I/II cases in the discovery dataset.
Frequency distribution of the number of SNPs with D’=1 relative to rs60745952 as determined in 200 permutations of stage IV cases in the discovery dataset.
The empirical null distributions for Stage I/II and Stage IV in the Validation dataset #1 are shown below:
Frequency distribution of the number of SNPs with D’=1 relative to rs60745952 as determined in 200 permutations of stage I/II cases in the validation dataset #1.
Frequency distribution of the number of SNPs with D’=1 relative to rs60745952 as determined in 200 permutations of stage IV cases in the validation dataset #1.
We performed a test between the two groups of the number of SNPs for which D’=1 based on the following assumptions: The null distribution of the permutation statistic is normally distributed. We have a sufficiently large number of permutation so that we can use a z score to perform the test (i.e. assume normality, with the permutation variance estimate, of the number of SNPs in the region for which D’=1). The observed count is denoted y. The variance from the permutation distribution is denoted V. The two groups are independent. Thus the variance of the difference between the two observed numbers is the sum of the variances, i.e. the variance of the difference is (V1+V2), letting 1 denote stages I/II and 2 denote stage IV. We perform a one-sided test of the observed group difference. The corresponding z-statistic is (y2-y1)/√(V1+V2). Table 3 in the text shows y, SD=√V, y2-y1 and SD=√(V1+V2). Except for the stage I/II validation dataset, the distributions are approximately normally distributed. The skewness of that distribution would tend to make the P-value conservative, i.e. too large. To verify that the assumption of normality was not critical, for each dataset we estimated the null distribution of the z-statistic as follows. We simulated 32 replicates from each group, noting the observed count and variance. We then paired each replicate from the stage I/II data with each replicate from the stage IV data to calculate 1024 replicate z-statistics. For each dataset, the z-statistic calculated from the observed counts given in Table 3 was larger than any of the simulated null distribution z-statistics, thus demonstrating that the p-values are robustly < 10-3.