Jul 19, 2004 - evaluation of trade-offs across the architecture/micro-architecture bound- ...... is a 2x2 gain matrix used to feedback the voltage model by the difference ...... [109] M. D'Angelo, Studio di algoritmi di localizzazione in reti radio ...
Project IST-2001-38314 COLUMBUS Design of Embedded Controllers for Safety Critical Systems
WPPBD: Platform Based Design
Platform-Based Design: Applications and Flow A. Balluchi, M. D. Di Benedetto, A. Ferrari, G. Girasole, F. Graziosi, F. Parasiliti, A. Pinto, R. Passerone, R. Petrella, A. Sangiovanni-Vincentelli, F. Santucci, M. Sgroi, M. Tursini, R. Alesii, S. Tennina
July 19, 2004
Version:
1
Task number: Deliverable number: Contract:
DPBD2,DPBD3, DDF1, DDF2 IST-2001-38314 of European Commission
DOCUMENT CONTROL SHEET Title of document: Authors of document: Deliverable number: Contract:
DPBD2, DPBD3, DDF1, DDF2 IST-2001-38314 of European Commission
2
Project:
Design of Embedded Controllers for Safety Critical Systems (Columbus)
DOCUMENT CHANGE LOG Version #
Issue Date
Sections affected
Relevant information
0.1
20 June 04
All
First draft
0.2
5 July 04
All
Second draft
0.3
10 July 04
All
Third draft
1
19 July 04
All
Final Version
Author(s) and Reviewers Authors A. Balluchi
Organisation
Signature/Date
AQUI
M.D. Di Benedetto
AQUI
A. Ferrari
PARADES
G. Girasole
AQUI
F. Graziosi
AQUI
F. Parasiliti
AQUI
R. Passerone
UCB
R. Petrella
AQUI
A. Pinto
UCB
A. Sangiovanni - Vincentelli
PARADES
&
UCB F. Santucci
AQUI
M. Sgroi
UCB
M.Tursini
AQUI
R. Alesii
AQUI
S. Tennina
AQUI
Internal reviewers P. Tognolatti S. Di Gennaro
AQUI AQUI
3
Platform-based Design: Applications and Flows A. Balluchi, M. D. Di Benedetto, A. Ferrari, G. Girasole, F. Graziosi, F. Parasiliti, A. Pinto, R. Passerone, R. Petrella, A. Sangiovanni-Vincentelli, F. Santucci, M. Sgroi, M. Tursini, R. Alesii, S. Tennina
Abstract Platform-based Design (PBD) is a relatively new methodology paradigm for the design of embedded systems. It has made significant inroads in the electronic industry (see for example the OMAP platform for cellular communication and the Nexperia Platform for multimedia). However, the concept means different things for different industrial sectors and for different design groups. An attempt at structuring this approach has been put forward by our research group. The basic aspects of the methodology are its meet-in-the-middle view of the design process where a combination of top-down and bottom-up processes define an approach that maximizes re-usability and verifiability while mantaining constraints on performance, cost and power consumption. We describe the general aspects of the methodoloogy and we give three applications to show how this method can be applied in a number of diffente industrial domain of great interests such as wireless sensor networks, automotive controllers and electric motor drives. The point here is to show that it is possible to adopt a general design methodology for all embedded system applications thus forming the basis for a well structured discipline that yields repeatable results and save substantial amount of expensive resources. In particular, the wireless sensor network domain presents several challenging problems, it is characterized by hard real-time constraints, it has to be fault tolerant and design-error free, and it has to react to a nondeterministic adversary environment. Ad hoc wireless sensor networks are designed for environmental monitoring application and we emphasize a methodology that favours re-use at all levels of abstraction. In particular, we used the platform-based design paradigms to identify an abstraction layer for the applications that is implementation independent
The goal is to design a sensor node which is able to reconfigure itself and to form a network without any need for expensive infrastructure. The design of automotive control systems is becoming increasingly complex due to the increasing level of performances required by car manufactures and the tight constraints on cost and development time imposed by the market. In this report, we illustrate the application of an integrated control-implementation design methodology, recently proposed by our group, to the development of the highest layers of abstraction in the design flow of an engine control system for motorcycles. Finally we show that an appropriate subset of the layers of abstraction used for the automotive application can also be used for the design of electric drives. The essential gain in this domain is the possibility of designing for non idealities of the computing platform at the functional level thus allowing for early detection of errors and short time-to-market while satisfying tight performance constraints.
2
Contents 1
Introduction
2
System Design Methodology
13
2.1
Function and Communication-based Design . . . . . . . . .
14
2.2
(Micro-)Architecture . . . . . . . . . . . . . . . . . . . . . . .
17
2.3
Mapping . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
18
2.4
Link to Implementation . . . . . . . . . . . . . . . . . . . . .
20
2.5
Platform-Based Design . . . . . . . . . . . . . . . . . . . . . .
20
2.5.1
The Overarching Conceptual View . . . . . . . . . . .
20
2.5.2
(Micro-) Architecture Platforms . . . . . . . . . . . . .
23
2.5.3
API Platform . . . . . . . . . . . . . . . . . . . . . . .
27
2.5.4
System Platform-Stack . . . . . . . . . . . . . . . . . .
29
2.5.5
A Formal Interpretation of Platform-based Design . .
30
3
5
The Platform-Based-Design Flow (Deliverable DDF1) 3.1
40
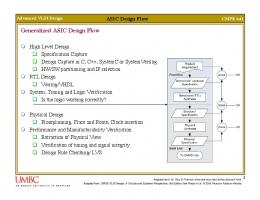
Logic Synthesis Flow as an Example of a Platform-based Design Flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
40
3.2
Levels of Abstractions in Multimedia System Design . . . .
43
3.3
Implementation of the Multimedia design flow in Metropolis
46
3.3.1
The Metropolis metamodel . . . . . . . . . . . . . . .
46
3.3.2
Functional Description . . . . . . . . . . . . . . . . . .
49
3
4
3.3.3
Architectural Platform . . . . . . . . . . . . . . . . . .
53
3.3.4
Mapping Strategy . . . . . . . . . . . . . . . . . . . . .
55
Platform-based Design for Wireless Ad-hoc Sensors-Network
59
4.1
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . .
59
4.2
A Standard for the Development of Implementation Independent Applications . . . . . . . . . . . . . . . . . . . . . . . 4.2.1
4.3
4.4
61
Ad-hoc Wireless Sensor Networks - Functional Architecture . . . . . . . . . . . . . . . . . . . . . . . . .
64
4.2.2
The Query/Command Services: the Core of the SNSP
69
4.2.3
Auxiliary Services . . . . . . . . . . . . . . . . . . . .
77
4.2.4
A Bridge to the AWSN Implementation . . . . . . . .
80
4.2.5
Summary . . . . . . . . . . . . . . . . . . . . . . . . .
82
Design of AWSN Using the PBD Paradigm . . . . . . . . . .
83
4.3.1
Communication Networks: OSI Reference Model . .
86
4.3.2
Network Platforms . . . . . . . . . . . . . . . . . . . .
89
4.3.3
Network Platform API . . . . . . . . . . . . . . . . . .
93
4.3.4
Quality of Service . . . . . . . . . . . . . . . . . . . . .
95
4.3.5
Classes of Communication Service . . . . . . . . . . .
96
4.3.6
Examples of Network Platforms . . . . . . . . . . . .
97
Example: AWSN Design for Location Service . . . . . . . . .
99
4.4.1
Application and Abstraction Layers . . . . . . . . . . 100
4.4.2
Propagation of requirements and mapping of parameters . . . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.4.3
Design Flow (Deliverable DDF2) . . . . . . . . . . . . . . . . . . . . 119
4.4.4 4.5 5
Further Issues . . . . . . . . . . . . . . . . . . . . . . . 138
Concluding Remarks and Future Work . . . . . . . . . . . . . 140
Integrated control-implementation design for automotive embedded controllers
142
4
5.1
Integrated control-implementation design of a motorcycle ECU145
5.2
From System Specification to Functional Decomposition . . 145
5.3
5.4
5.5
5.2.1
Functional platform. . . . . . . . . . . . . . . . . . . . 145
5.2.2
Functional refinement. . . . . . . . . . . . . . . . . . . 147
5.2.3
ECU functional design. . . . . . . . . . . . . . . . . . 148
From Functional Decomposition to Control Strategies . . . . 150 5.3.1
Control platforms. . . . . . . . . . . . . . . . . . . . . 150
5.3.2
Control refinement. . . . . . . . . . . . . . . . . . . . . 150
5.3.3
ECU control strategies design. . . . . . . . . . . . . . 151
From Control Strategies to Implementation Abstract Model . 152 5.4.1
Implementation platforms. . . . . . . . . . . . . . . . 152
5.4.2
Implementation abstract model refinement. . . . . . . 154
5.4.3
ECU implementation abstract model design. . . . . . 155
Design Flow for Automotive Control Design (Deliverable DDF2) . . . . . . . . . . . . . . . . . . . . . . . . 157
5.6 6
Concluding Remarks and Future Work . . . . . . . . . . . . . 159
Platform–based design for electrical motor drives
160
6.1
Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 160
6.2
Platform-Based-Design approach for electrical drives . . . . 163
6.3
An application of PBD design approach: sensor-less control of electrical drives . . . . . . . . . . . . . . . . . . . . . . . . . 165
6.4
6.3.1
Sensor-less control of electrical drives . . . . . . . . . 165
6.3.2
Sensor-less control of IPM motors . . . . . . . . . . . 167
6.3.3
Sensor-less drive scheme . . . . . . . . . . . . . . . . 169
6.3.4
Signal injection technique . . . . . . . . . . . . . . . . 170
6.3.5
Kalman filtering . . . . . . . . . . . . . . . . . . . . . 172
6.3.6
Demodulation strategy: carrier recovery . . . . . . . 173
6.3.7
Adaptive observer for the IPM motor . . . . . . . . . 176
Simulation of the continuous time ideal drive system . . . . 180 6.4.1
Signal injection based estimation engine . . . . . . . . 181
5
6.5
6.4.2
Motor model . . . . . . . . . . . . . . . . . . . . . . . 183
6.4.3
Coordinate transformations . . . . . . . . . . . . . . . 184
6.4.4
Results of the continuous time ideal drive system . . 188
6.4.5
Results with off-line estimation . . . . . . . . . . . . . 189
6.4.6
Results with on-line estimation . . . . . . . . . . . . . 190
Introduction of platform specific implementation constraints 193 6.5.1
Finite precision fixed-point numerical representation
196
6.5.2
Quantisation of measured values . . . . . . . . . . . . 197
6.5.3
Control loop delay (or latency time) . . . . . . . . . . 198
6.5.4
Actuation delay (due to the presence of the power converter) . . . . . . . . . . . . . . . . . . . . . . . . . 198
6.5.5
Simulation of the drive system adopting platform specific implementation constraints . . . . . . . . . . . . 200
6.5.6
Introducing actuation delay and measurements quantisation . . . . . . . . . . . . . . . . . . . . . . . . . . . 205
6.6
6.7
The drive controller and hardware interface . . . . . . . . . . 208 6.6.1
The eZdsp LF2407 controller . . . . . . . . . . . . . . 210
6.6.2
Current measurement interface . . . . . . . . . . . . . 211
6.6.3
Incremental encoder interface . . . . . . . . . . . . . . 212
Known problems when going from simulation to implementation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 214 6.7.1
6.8
6.9
Implementation of a digital integrator . . . . . . . . . 215
Control of PMSM with encoder . . . . . . . . . . . . . . . . . 224 6.8.1
Initialisation of the rotor position . . . . . . . . . . . . 224
6.8.2
Hardware device drivers . . . . . . . . . . . . . . . . 227
6.8.3
Rotor position and speed measurement . . . . . . . . 230
6.8.4
Experimental results . . . . . . . . . . . . . . . . . . . 235
Platform-Based design flow for electrical drives (Deliverable DDF2) . . . . . . . . . . . . . . . . . . . . . . . . 237
7
Conclusions
241
6
List of Figures 2.1
Overall Organization of the Methodology [1] . . . . . . . . .
14
2.2
Platforms, Mapping Tools and Platform Stacks [2] . . . . . .
22
2.3
Layered software structure (Source: A. Ferrari) [2] . . . . . .
28
2.4
System platform stack [2] . . . . . . . . . . . . . . . . . . . .
29
2.5
Mapping of function and architecture . . . . . . . . . . . . .
36
2.6
Mapping of function and architecture . . . . . . . . . . . . .
37
3.1
Platform based representation of a simplified logic synthesis flow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
42
3.2
Platform stack for multimedia designs . . . . . . . . . . . . .
44
3.3
Action automata for the assignment expression y = x + 1 which contains the subexpression x + 1.
. . . . . . . . . . .
47
3.4
Block diagram representation of the picture-in-picture example 50
3.5
ht . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.6
Structure of the netlist used to refine a yapichannel using a bounded FIFO ttlmedium . . . . . . . . . . . . . . . . . . . .
51 52
3.7
Block diagram of the architecture platform netlist in Metropolis 53
3.8
Example of task . . . . . . . . . . . . . . . . . . . . . . . . . .
3.9
Graphical representation of the architecture execution seman-
55
tics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
56
3.10 Part of the code that implements the mapping . . . . . . . .
57
7
4.1
Functional model of an AWSN as a set of controllers (a) interacting with the environment and among each other; (b) interacting with the environment through a set of spatially distributed sensors and actuators; (c) interacting with the environment through a unified Application Interface (AI). Observe that interactions between the controllers themselves are now supported through the same paradigm. . . . . . . .
65
4.2
Query Service interactions . . . . . . . . . . . . . . . . . . . .
71
4.3
Query Service execution. Controller/QS interactions are defined by the AI, while the QS/Sensor interface is implementation dependent and might follow for example the IEEE 1451.2 standard . . . . . . . . . . . . . . . . . . . . . . . . . .
75
4.4
Mapping Application and SNSP onto a SNIP . . . . . . . . .
82
4.5
OSI-RM layering structure [3] . . . . . . . . . . . . . . . . . .
87
4.6
Process Composition in TSM . . . . . . . . . . . . . . . . . .
91
4.7
Examples of NPIs (base) [3] . . . . . . . . . . . . . . . . . . .
97
4.8
Examples of NPIs (refinement) [3] . . . . . . . . . . . . . . .
98
4.9
Wireless NPIs [3] . . . . . . . . . . . . . . . . . . . . . . . . .
98
4.10 Overall Organization of the Methodology . . . . . . . . . . . 103 4.11 6-Way Handshaking Protocol . . . . . . . . . . . . . . . . . . 111 4.12 Network Configuration Example . . . . . . . . . . . . . . . . 112 4.13 Receiver’s Synchronization State Machine . . . . . . . . . . . 115 4.14 Parameters Mapping among Platforms . . . . . . . . . . . . . 118 4.15 Design Flow Methodology . . . . . . . . . . . . . . . . . . . . 120 4.16 MSN diagram for positioning process (1) . . . . . . . . . . . 122 4.17 Nodes not able to enter refinement phase . . . . . . . . . . . 123 4.18 End of Refinement . . . . . . . . . . . . . . . . . . . . . . . . 124 4.19 Proposed DL, receive side (connection phase) . . . . . . . . . 126 4.20 Proposed DL, receive side (data exchange phase) . . . . . . . 128 4.21 Proposed DL, transmit side . . . . . . . . . . . . . . . . . . . 129
8
4.22 Representation of the generic node within OMNeT++ . . . . 131 4.23 Constrained Minimization of the Error Functional . . . . . . 134 4.24 Simulation Screenshot example . . . . . . . . . . . . . . . . . 136 4.25 Nodes localized with Number of Anchors variable (without (wf) and with feedback) with a position error less than 10% w. r. t. radio range . . . . . . . . . . . . . . . . . . . . . . . . . 137 4.26 Percentage of localized nodes w. r. t. connectivity value . . . 138 4.27 Error of positioning (top) and accuracy level (bottom) . . . . 139 4.28 Sensor Network Platform with Vertical Module . . . . . . . . 140 5.1
Functional decomposition. . . . . . . . . . . . . . . . . . . . . 146
5.2
General scheme for the functional design. . . . . . . . . . . . 147
5.3
Refinement of the functional decomposition . . . . . . . . . . 150
5.4
AFR control parameter admissible set J(c) ≤ 0, for settling time specification J1 (gray) and overshoot specification J2 (cyan). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
5.5
Abstract representation of the effects of implementation non– idealities. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 153
5.6
Values of the platform parameter Tc that guarantee settling time specification J1 (top) and overshoot specification J2 (bottom), for admissible control parameters (KP , KI ). . . . . 156
5.7
The Design Flow. . . . . . . . . . . . . . . . . . . . . . . . . . 158
5.8
Detailed control algorithms implementation design step. . . 158
6.1
sensor-less drive scheme. . . . . . . . . . . . . . . . . . . . . . 170
6.2
Digital PLL adopted for carrier recovery. . . . . . . . . . . . . 175
6.3
Flux and current space vectors in an IPM synchronous motor. 177
6.4
Flux observer. . . . . . . . . . . . . . . . . . . . . . . . . . . . 177
6.5
Adaptive magnet flux and speed observer. . . . . . . . . . . 179
6.6
The control system under VisSim environment. . . . . . . . . 181
6.7
Signal injection based estimation engine. . . . . . . . . . . . 182
9
6.8
Signal injection implementation. . . . . . . . . . . . . . . . . 182
6.9
Calculation of quadrature-axis flux. . . . . . . . . . . . . . . 185
6.10 Calculation of direct-axis flux. . . . . . . . . . . . . . . . . . . 185 6.11 Calculation of quadrature-axis current. . . . . . . . . . . . . . 185 6.12 Calculation of direct-axis current. . . . . . . . . . . . . . . . . 185 6.13 Calculation of electromagnetic torque. . . . . . . . . . . . . . 185 6.14 Calculation of rotor speed. . . . . . . . . . . . . . . . . . . . . 186 6.15 Rotor position equation. . . . . . . . . . . . . . . . . . . . . . 186 6.16 Floating-point discrete-time integrator. . . . . . . . . . . . . . 186 6.17 Coordinate transformation at the motor model input side. . 187 6.18 Coordinate transformation at the motor model output side. . 187 6.19 Speed step response (estimator off-line). . . . . . . . . . . . . 189 6.20 Rotor position estimation error (estimator off-line). . . . . . . 190 6.21 Electromagnetic torque and q-axis current component (estimator off-line). . . . . . . . . . . . . . . . . . . . . . . . . . . . 191 6.22 Speed step response (estimator on-line, sensor-less operations).192 6.23 Rotor position estimation error (estimator on-line). . . . . . . 192 6.24 q-axis and d-axis current components (estimator on-line). . . 193 6.25 Motor phase current processing including quantisation effects.198 6.26 Simulation model by adopting some implementation constraints. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200 6.27 Estimated phase angle of the demodulation signal. . . . . . . 202 6.28 Rotor position estimation error when control loop delay is neglected. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203 6.29 Rotor position estimation error when control loop delay is modelled. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204 6.30 q-axis current component. . . . . . . . . . . . . . . . . . . . . 205 6.31 Simulation model after modelling actuation model. . . . . . 206 6.32 Compare unit and inverter. . . . . . . . . . . . . . . . . . . . 206 6.33 Speed step response. . . . . . . . . . . . . . . . . . . . . . . . 208
10
6.34 Comparison between reference and actual q-axis current. . . 209 6.35 Comparison between reference and actual q-axis current. . . 209 6.36 TMS320LF2407 eZdsp block diagram. . . . . . . . . . . . . . 211 6.37 Principal electrical parameters of the current transducer as a function of the chosen primary number of turns. . . . . . . . 212 6.38 Post analog-to-digital conversion current scaling. . . . . . . . 213 6.39 Simulation verification of the 16-bit discrete integrator function. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 216 6.40 Experimental verification of the 16-bit discrete integrator function. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 217 6.41 Simulation verification of the 16-bit discrete integrator plus sinusoidal function. . . . . . . . . . . . . . . . . . . . . . . . . 218 6.42 Experimental verification of the 16-bit discrete integrator plus sinusoidal function. . . . . . . . . . . . . . . . . . . . . . . . . 218 6.43 Simulation verification of the 32-bit discrete integrator function. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 219 6.44 Experimental verification of the 32-bit discrete integrator function. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 220 6.45 Initialisation of rotor position: switching between two different sets of values. . . . . . . . . . . . . . . . . . . . . . . . 226 6.46 Initialisation state generator. . . . . . . . . . . . . . . . . . . . 227 6.47 Parametric control scheme. . . . . . . . . . . . . . . . . . . . 227 6.48 Input channel device driver and dialog window. . . . . . . . 228 6.49 Quadrature encoder device driver. . . . . . . . . . . . . . . . 228 6.50 Inverter device driver and dialog window. . . . . . . . . . . 229 6.51 Space vector PWM algorithm and inverter driver. . . . . . . 230 6.52 Calculation of the rotor mechanical position in term of encoder pulses. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231 6.53 Rotor electrical position calculation. . . . . . . . . . . . . . . 231 6.54 Transient and steady-state speed quantisation errors. . . . . 233
11
6.55 Speed quantisation errors. . . . . . . . . . . . . . . . . . . . . 234 6.56 Accumulation of the mechanical rotor position increments. . 234 6.57 Rotor speed calculation block diagram. . . . . . . . . . . . . 235 6.58 Open loop generation of compare values. . . . . . . . . . . . 236 6.59 Open loop current control: measured and sampled phase currents. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236 6.60 Open loop current control: phase current and sector. . . . . . 237 6.61 Speed control: measured rotor electrical position and phase current. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 238 6.62 Speed step response. . . . . . . . . . . . . . . . . . . . . . . . 238 6.63 Design flow. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 240
12
List of Tables 4.1
Query Service primitives . . . . . . . . . . . . . . . . . . . . .
72
4.2
Primitives used for the interaction with Virtual Sensors . . .
76
6.1
Adopted IPM motor parameters . . . . . . . . . . . . . . . . 183
Columbus IST-2001-38314 WPBD
Page 4
Chapter 1
Introduction Embedded systems today are the core of most consumer products as well as industrial automation processes and transportation systems. This new market includes small and mobile devices that provide information, entertainment and communication features. These Embedded Systems require complex design and integration to be achieved in the short time frame of consumer electronics. The design challenge is the expansion of this spectrum of diversity and the implementation of a set of functionalities satisfying a number of constraints, ranging from performance to cost, emission, power, consumption, weight and form factor. The functionalities to be implemented in embedded systems have grown in number and complexity so much that the development time is increasingly difficult to predict. This complexity increase, coupled with the evolving specifications, has forced designers to look at implementations that are intrinsically flexible. The increase in computational power of processors and the corresponding decrease in size and cost have allowed the transfer of functionalities from hardware to software to achieve the desired flexibility. The overall goal of electronic embedded system design is to balance production costs with development time and cost, in view of performance
Page 5
Columbus IST-2001-38314 WPBD
Introduction
and functionality considerations. Minimizing production cost is the result of a balance between competing criteria. If one considers an integrated circuit implementation, the size of the chip is an important factor in determining production cost. Minimizing the size of the chip implies tailoring the hardware architecture to the functionality of the product. As a consequence, one could determine in the Integrated Circuit world a common hardware denominator (which is referred to as a hardware platform), that could be shared across multiple applications in a given application domain. Therefore, increasing in production volume may eventually cause a (much) lower decrease in overall costs than in the case when the chip is customized for the application. Of course, while production volume will drive overall cost down, it is important to consider even the final size of the implementation as well as the functionality and performance the platform should support. Today the choice of a platform architecture and implementation is much more an art than a science. In [1] it is believed that in the next-generation, successful system design methodology must assist designers in the process of designing, evaluating, and programming such platform architectures, with metrics and with early assessments of the capability of a given platform to meet design constraints. As the complexity of the products and related design increase, development efforts increase dramatically: there are problems in verifying design correctness. This is a critical aspect of embedded systems, since several application domains, such as automotive or environment monitoring, are characterized by safety considerations that are certainly not interesting for traditional PC-like software applications. Embedded controllers for safety critical systems presents the most challenging problems: it is characterized by hard real-time constraints, it has to be fault tolerant and design-error free, and it has to react to a non-deterministic hostile environment. To dominate these effects and, at the same time, meet the design time requirements, a
Columbus IST-2001-38314 WPBD
Page 6
design methodology that favours reuse and early error detection is essential. Both reuse and early error detection imply that the design phases must be defined carefully: all activities have to be clearly identified. Thus, a design methodology that addresses such complex embedded systems must start at high levels of abstraction [1]. Integrated Circuit designers, for example, work with abstraction layers too close to implementation and as a consequence, they experience several problems in sharing knowledge among different working groups. In addition, verifying the correctness of the design before building a physical prototype is very difficult. Most IC designers use Register Transfer Language (RTL), assembly or, at best, C description languages in order to capture the behaviour of their components, but these levels are clearly too low for complex system design. In particular, it is believed that the lack of appropriate methodology and tool support for modeling of concurrency in its various forms is an essential limiting factor in the use of commonly used programming languages to express design complexity [1]. Only by taking a global, high-level view of the problem, can we devise solutions that are going to have a real impact on the design of embedded systems. On one hand, starting from a high-level abstraction requires that we define the system functionality that is completely implementation independent and we keep solid theoretical foundations for formal analysis. On the other hand, we need to select a platform that can support the functionality meeting physical and user constraints about the final implementation. Our ultimate goal is to create a library of functions, along with associated hardware and software implementations, that can be used for all designs. It is important to have multiple levels of functionality supported in such a library, since lower levels, that are closer to the physical implementation, may often change because of the advances in technology, while higher levels tend to be more stable across product versions. Finally, we believe the preferred approaches to the implementation of complex embedded systems should include the following aspects [1].
Page 7
Columbus IST-2001-38314 WPBD
Introduction
• Design time and cost are likely to dominate the decision-making process for system designers. Therefore, design reuse in all its shapes and forms, as well as just-in-time, low-cost design-debug techniques, will be of paramount importance. Flexibility is essential to be able to map an ever-growing functionality onto a continuously evolving problem domain and set of associated hardware implementation options. • Designs must be captured at the highest level of abstraction to be able to exploit all the degrees of freedom that are available. Such a level of abstraction should not make any distinction between hardware and software, since such a distinction is the consequence of some design decision. • The implementation of efficient, reliable, and robust approaches to the design, implementation, and programming of concurrent systems is essential. In essence, whether the silicon is implemented as a single large chip or as a collection of smaller chips interacting across a distance, the problems associated with concurrent processing and concurrent communication must be dealt with in a uniform and scalable manner. In any large-scale embedded systems program, concurrency must be considered as a crucial aspect at all levels of abstraction and in both hardware and software. • Concurrency implies communication among components of the design. Communication is too often intertwined with the behaviour of the components of the design, so that it is very difficult to separate the two domains. Separating communication and behaviour is essential to dominate system design complexity. In particular, if behaviours and communications are intertwined in a design component, it is very difficult to re-use components, since their behaviour is tightly dependent on the communication with other components of the original design. In addition, communication can be described
Columbus IST-2001-38314 WPBD
Page 8
at various levels of abstraction, thus exposing the potential of implementing communication behaviour in many different forms according to the available resources. Today this freedom is often not exploited. • Next-generation systems will most likely use a few highly complex (Moore’s Law Limited) part-types, but many more energy/powercost-efficient, medium-complexity (O(10M-100M) gates in 50nm technology) chips, working concurrently to implement solutions to complex sensing, computing, and signalling/actuating problems. These chips will most likely be developed as an instance of a particular platform. That is, rather than being assembled from a collection of independently developed blocks of silicon functionality, they will be derived from a specific family of micro-architectures, possibly oriented toward a particular class of problems, that can be modified (extended or reduced) by the system developer. These platforms will be extended mostly through the use of large blocks of functionality (for example, in the form of co-processors), but they will also likely support extensibility in the memory/communication architecture as well. When selecting a platform, cost, size, energy consumption and flexibility must be taken into account. Since a platform has much wider applicability than ASICs, design decisions are crucial. A less than excellent choice may result in economic debacle. Hence, design methods and tools that optimize the platform-selection process are very important. • Platforms will be highly programmable, at a variety of levels of granularity. Because of this feature, mapping an application into a platform efficiently will require a set of tools for software design that resemble more and more logic synthesis tools. This is believed to represent a very fruitful research area.
Page 9
Columbus IST-2001-38314 WPBD
Introduction
Platform-based Design (PBD) is a relatively new methodology paradigm for the design of embedded systems that addresses most of the aspects outlined above. It has already made significant inroads in the electronic industry (see for example the OMAP platform for cellular communication and the Nexperia Platform for multimedia). However, the concept means different things for different industrial sectors and for different design groups. An attempt at structuring this approach has been put forward by our research group. The basic aspects of the methodology are its meet-in-themiddle view of the design process where a combination of top-down and bottom-up processes define an approach that maximizes re-usability and verifiability while mantaining constraints on performance, cost and power consumption. We describe the general aspects of the methodoloogy and we give three applications to show how this method can be applied in a number of diffente industrial domain of great interests such as wireless sensor networks, automotive controllers and electric motor drives. The point here is to show that it is possible to adopt a general design methodology for all embedded system applications thus forming the basis for a well structured discipline that yields repeatable results and save substantial amount of expensive resources. The methodology has a dual use: on one hand, for relatively well established disciplines, it can cast best engineering practices in a fairly rigorous framework thus allowing a considerable reduction in design time and effort, and the wide adoption of a common view of the design process across engineering organizations that can be geographically and intellectually quite distant as documented by the results in the automotive industry. On the other hand, it can provide breakthroughs in new design domains by providing abstractions and processes that make it possible to create an industry as in the case of wireless sensor networks where we are in the process of proposing a standard for the interface between applications and underlying phyisical wireless networks.
Columbus IST-2001-38314 WPBD
Page 10
In this deliverable, we first present the basic tenet of a design methodology based on separation or orthogonalization of concerns and we introduce the concept of platform-based design(Chapter 2). In Chapter 3, we present a flow for Platform-Based Design that shows how to use the PBD principles to go from specifications to implementation. In particular, we show that traditional flows such as the logic synthesis flow can be cast in terms of PBD. In addition, we will present a method to the design of a Picture-in-Picture subsystem of a digital TV product as an example of the application of the flow (Deliverable DDF1). In Chapter 4, we show an application of the system design ideas presented in the previous chapters and, in particular, we demonstrate how the methodology can be used to: • Define novel layers of abstraction and interfaces that allow the development of applications semi-independently from the implementation detail of the underlying network; • Build a generalized platform for ad hoc wireless networks. In particular, we present our proposed solution for the Data Link (DL) algorithm in these networks. In the sequel, we give an overview about the TinyOS/nesC, which are the operating system and the programming language, respectively, of MICA2 motes. • design a location algorithm and subsystem with an accompanying design flow (Deliverable DDF2). In Chapter 5, we present the application of the PBD methodology to the design of automotive systems and we use the design of a motorcycle engine controller as a demonstrator of the paradigms we support. We also detail a design flow for this application (Deliverable DDF2). In Chapter 6, we present the application of PBD to the design of electric motor drives to minimize time-to-market while satisfying performance
Page 11
Columbus IST-2001-38314 WPBD
Introduction
constraints. Also in this case, we conclude the Chapter describing a design flow (Deliverable DDF2). We believe we described here a general methodology and the associate design flow that can have a significant impact on design and on tools.
Columbus IST-2001-38314 WPBD
Page 12
Chapter 2
System Design Methodology An essential component of a new system design paradigm is the orthogonalization of concerns (we refer to orthogonalization, like orthogonal bases in mathematics, against separation to stress the independence of the axes along which we perform the “decomposition”), i.e. the separation of the various aspects of design to allow more effective exploration of alternative solutions. An example of this paradigm is the orthogonalization between functionality and timing exploited in the synchronous design methodology that has been so successful in digital design. In this case, provided that signal propagation delays in combinatorial blocks are all within the clock cycle, the check of correct behaviour of the design is restricted to the functionality of combinatorial blocks, thus achieving a major design speed-up factor versus the more liberal asynchronous design methodology. Other more powerful paradigms must be applied to system design to make the problem solvable, let alone efficiently so. One pillar of a design methodology that has been proposed over the years [7, 8, 9] is the separation between:
• Function (what the system is supposed to do) and architecture (how it does it);
Page 13
Columbus IST-2001-38314 WPBD
System Design Methodology
Figure 2.1: Overall Organization of the Methodology [1] • Communication and computation. The mapping of function to architecture is an essential step from conception to implementation. An industrial example is the topic of HardwareSoftware Co-design. The problem to be solved is coordinating the design of the parts of the system to be implemented as software and the parts to be implemented as hardware blocks, avoiding the HW/SW integration problem. Worrying about hardware-software boundaries without considering higher levels of abstraction may be a wrong approach. HW/SW design and verification happens after some essential decisions have been already made, and this is what makes the verification and the synthesis problem hard. SW is really the form that a behaviour is taking if it is mapped into a programmable microprocessor or DSP. Motivations behind the preference for SW design against the HW one can be the performance of the application on a particular processor, or the need for flexibility and adaptivity. The origin of the HW and SW separation problem is in the behaviour that the system must implement. The choice of an architecture, i.e. of a collection of components that can be either software programmable, re-configurable or customized, is the other important step in design. The basic tenet of the proposed design methodology is shown in Figure 2.1 below and it is detailed in the next sections.
2.1
Function and Communication-based Design
Generally, a system implements a set of functions, where a function is an abstract view of the behaviour of an aspect of the system. This set of functions is the input/output characterization of the system with respect to its environment. There is no notion of implementation associated with it. For
Columbus IST-2001-38314 WPBD
Page 14
2.1 Function and Communication-based Design
example, when the engine of a car starts (input), the display of the number of revolutions per minute of the engine (output) is a function, while when the engine starts, the display in digital form of the number of revolutions per minute on the LCD panel is not a function. In the latter case, it is already decided that the display device is an LCD and that the format of the data is digital. The notion of function strongly depends on the level of abstraction in which the design is referred to. For example, the decision whether to use a LCD display or some other visual indication about the engine revolutions per minute may not be a free parameter of the design. However, even in this case, it is important to realize that there is a higher level of abstraction where the decision about the type of signal is taken. This may lead to develop new paradigms, that were not even considered before because of the entry level of the design. The point is that no design decision should ever be made implicitly and that capturing the design at higher levels of abstraction yields better designs in the end. If there are design decisions to be made, then they are grouped in a design phase called function design. The description of the function the system has to implement is captured using a particular language that may or may not be formal. The languages most widely used today for capturing functional specifications are application dependent. For example, for control applications Matlab is typically adopted. However, these languages often do not have the semantic constructs needed to specify concurrency. The most important point for functional specification should be the underlying mathematical model, often called model of computation. The most significant models of computation that have been proposed are based on three basic concepts: Finite State Machines, Data Flow and Discrete Events [13, 14]. All models have their strengths and weaknesses, and an important differentiating factor is the ability to use these models at their best. It is to be remarked that each model is composable (can be assembled) in a particular way, which guarantees that some properties of sin-
Page 15
Columbus IST-2001-38314 WPBD
System Design Methodology
gle components are maintained in the overall system. Communication and time representation in each model of computation are strictly intertwined. In fact, in a synchronous system, communication can take place only at precise instants of time, thus reducing the risk of unpredictable behaviours. Synchronous systems are notoriously more expensive to implement and often less performing, thus opening the door to asynchronous implementations may be the winning choice. In this latter case, which is often the choice for large safety critical system design, particular care has to be exercised to avoid undesired and unexpected behaviours. The balance between synchronous and asynchronous implementations is likely the most challenging aspect of system design. The view of communication in these models of computation is often addressed at a low level of abstraction. It would be opportune to be able to specify abstract communication patterns with high-level constraints, which do not imply yet a particular model of communication. For example, an essential aspect of data communication is the loss-lessness feature: there must exist a level of abstraction that is high enough to require that communication takes place with no data losses. For example, Kahn process networks [14] are important Data Flow models, that guarantee loss-less communication at the highest level of abstraction by assuming an ideal buffering scheme that has unbounded buffer size. Clearly, the unbounded buffer size is a non-implementable way of guaranteeing loss-lessness. When moving towards implementable designs, this assumption has to be removed. A buffer can be provided to store temporarily data that are exchanged among processes, but it must be of finite size. Hence, the choice of the buffer size is crucial. Unfortunately, deciding whether a finite buffer implementation exists that guarantees loss-lessness is not theoretically feasible in the general case, but there are cases for which the optimal buffer size can be found. In general, buffer overwriting could occur and the designer needs for additional mechanisms, that composed with the finite buffer implementation
Columbus IST-2001-38314 WPBD
Page 16
2.2 (Micro-)Architecture
still guarantee that no loss takes place. For example, a send-receive protocol can be used to prevent buffer over-write to occur. Note that in this case the refinement process may be quite complex and involves the use of composite processes. This particular example will be take again in consideration in the last section of Section 4, in order to better explain our methodology. Approaches to the isolation of communication and computation, and how to refine the communication specification towards an implementation have been presented in [15]. In some cases, the designer has been able to determine a synthesis procedure for the communication that guarantees some properties. Clearly, this formalism and the successive refinement process opens a very appealing perspective to system design with unexplored opportunities in component-based software design.
2.2
(Micro-)Architecture
In most design approaches, the next stage of the design process involves the evaluation of trade-offs across the architecture/micro-architecture boundary, and the class of structural compositions that implement the architecture is of primary concern. While the word architecture is used in many meanings and contexts (the reader can refer to [1]) for examples, we adhere to the definitions introduced in [16]: the architecture defines an interface specification that describes the functionality of an implementation, while being independent of the actual implementation. The micro-architecture, on the other hand, defines how this functionality is actually realized as a composition of modules and components, along with their associated software. The instruction-set architecture of a microprocessor is a good example of an architecture: it defines what functions the processor supports, without defining how these functions are actually realized. The microarchitecture of the processor is defined by the organization and the hardware of the processor. These terms can easily be extended to cover a much wider
Page 17
Columbus IST-2001-38314 WPBD
System Design Methodology
range of implementation options. At this point, the design decisions are made concerning what will eventually be implemented as software or as hardware. Consistent with the above definitions, a micro-architecture is a set of interconnected components (either abstract or with a physical dimension) that is used to implement a function. For example, the LCD, a physical component of a micro-architecture, can be used to display the number of revolutions per minute of the automotive engine, which we referred above. In this case, the component has a concrete, physical representation. In other cases, its representation may be more abstract. In general, a component is an element with specified interfaces and explicit context dependency. The micro-architecture determines the final hardware implementation and hence it is strictly related to the concept of (hardware) platform [2] that will be presented in greater detail later. The most important micro-architecture for the majority of embedded safety critical designs consists of microprocessors, peripherals, dedicated logic blocks and memories. In the case of automotive body electronics, the actual placement of the electronic components inside the body of the car and their interconnections is kept mostly fixed, while the single components, i.e., the processors, may vary to a certain extent. A fixed micro-architecture simplifies the design problem, but limits design optimality. The trade-off is not easy to achieve. In addition, the communication among micro-architecture blocks must be handled with great care: its characteristics can make the composition of blocks easy or difficult to achieve. Standards are useful to achieve component re-use and a bus is typical interconnection structures intended to favor re-use. Unfortunately, the specification of standard busses is hardly formal.
2.3
Mapping
The essential design step that connects the different abstraction layers is the mapping process, where the functions to be implemented are assigned
Columbus IST-2001-38314 WPBD
Page 18
2.3 Mapping
(mapped) to the components of the micro-architecture. For example, the computations needed to display a set of signals may all be mapped to the same processor or to two different components of the micro-architecture (e.g., a microprocessor and a DSP). The mapping process determines the performance and the cost of the design. As we said above, to measure the performance of the design and its cost in terms of used resources, it is often necessary to complete the design. We look for a more rigorous design methodology. In the mapping step, our choice is dictated by estimates of the performance of that implemented function onto the micro-architecture component. Estimates can be provided either by the manufacturers of the components or by system designers. Experts designers use some analysis tool to develop estimation models, that can be easily evaluated to allow for fast design exploration and yet are accurate enough to choose a good micro-architecture. Given the importance of this step in any application domain, automated tools and environments should support effectively the mapping of functions to micro-architectures. The output of this step consists in one of the following alternatives.
• A mapped micro-architecture, iteratively refined towards the final implementation with a set of constraints on each mapped component (derived from top-level design constraints); or • A set of diagnostics for the selection phase of micro-architecture and function, whereas the estimation process will signal that design constraints may not be met with the present micro-architecture and function set. In this case, if possible, an alternative micro-architecture is selected. Otherwise, the designer needs to work in the function space by either reducing the number of functions to be supported or their demands in terms of performance.
Page 19
Columbus IST-2001-38314 WPBD
System Design Methodology
2.4
Link to Implementation
This phase is entered once the mapped micro-architecture has been estimated as capable of meeting the design constraints: in our case, they have to be met the safety critical ones. The next major issue to be tackled is building the components of the micro-architecture. This requires the development of appropriate hardware or software, that enable the programmable hardware platform to perform its task. This step leads the design to its final implementation stage. The hardware block may be found in an existing library or may need a special purpose implementation as dedicated logic based on existing library of components. Also the software components may exist already in an appropriate library or may need further decomposition into a set of sub-components. Thus, either in hardware or software, the need for a customized component expose us to what reference [1] calls the fractal nature of design, i.e., the design problem repeats itself at every level of the design hierarchy into a sequence of nested function (also called architecture)–micro-architecture–mapping processes.
2.5
Platform-Based Design
Once we have analyzed the general view of the methodology plan, we have to formalize the design methodology in a structured set of elements. In this frame, we will examine the Platform Based Design (PBD) features, as defined in [2].
2.5.1
The Overarching Conceptual View
Various forms of platform-based design have been used for many years. The basic advantages of PBD are as follows [2]: • It lies the foundation for developing economically feasible design flows because it is a structured methodology that theoretically lim-
Columbus IST-2001-38314 WPBD
Page 20
2.5 Platform-Based Design
its the space of exploration, yet still achieves superior results in the fixed time constraints of the design. A platform is an abstraction layer in the design flow that facilitates a number of possible refinements into a subsequent abstraction layer in the design flow. The design process progresses through a series of platforms and each platform layer defines bounds for what is achievable by mapping into it, while offering faster design and lower risk. • It provides a formal mechanism to indentify the most critical hand-off points in the design chain: the hand-off point between system companies and IC design companies and the one between IC design companies and manufacturing companies represent the articulation points of the overall design process. For instance, semiconductor companies need to minimize risks when designing standardized chips. Hence, they need to have a fairly complete characterization of the application spaces they wish to target together with the associated constraints in terms of affordable costs and performance levels. By the same token, system companies need to have an accurate characterization of the capabilities of the chips in terms of performance such as power consumption, size and timing, as well as “Application Program Interfaces” (APIs) that allow the mapping of their application into the chip at a fairly abstract level. APIs must then support a number of tools to ease the possibly automatic generation of the personalization of the programmable components of the chips. • It eliminates costly design iterations because it enables derivative design, i.e. the technique of building an application-specific product by assembling and configuring platform components in a rapid and reliable fashion. For instance, a hardware platform is a family of architectures satisfying a set of constraints imposed to allow reuse of hardware and software components. Then, an API platform can be developed to effectively extend the hardware platform toward the
Page 21
Columbus IST-2001-38314 WPBD
System Design Methodology
Figure 2.2: Platforms, Mapping Tools and Platform Stacks [2] application software, thus enablng quick, reliable, derivative design. • Regarding design as a meeting-in-the-middle process where successive refinements of specifications meet with abstractions of potential implementations. • The identification of precisely defined layers (platforms), where the refinement and abstraction processes take place. The layers then support designs built upon them, where upper layers are isolated from lower-level details but letting enough information transpire about lower levels of abstraction. This is oriented to allow design space exploration with a fairly accurate prediction of the final implementation properties. The information should be incorporated in appropriate parameters that annotate design choices at the present layer of abstraction. The general definition of a platform, that we recall from [2], is an abstraction layer in the design flow that facilitates a number of possible refinements into a subsequent abstraction layer (platform) in the design flow. The mille feuilles of Figure 2.2 is a sketch of the design process as a succession of abstraction layers. The analogy covers also the filling between consecutive layers. This filling corresponds to the set of methods and tools that allow to map the design from one abstraction layer to the next one. Often, the combination of two consecutive layers and their filling can be interpreted as a unique abstraction layer with an upper view (the top abstraction layer) and a lower view (the bottom layer). So, every pair of platforms, the tools and methods which are used to map the upper layer of abstraction into the lower level one is a platform stack. It can be noted that a platform stack may include several sub-stacks if the designer wishes to span a large number of abstractions. This could de-
Columbus IST-2001-38314 WPBD
Page 22
2.5 Platform-Based Design
pend on the sub-groups of competences. An example is when the physical layer designers meet in the middle the constraints of DataLink protocol layer ones in building two prototypes that need to perform a point-to-point communication: next in this deliverable we better detail this. Now, let simply note that the larger the span is, the more difficult will be to map effectively the two, but the greater will be the potential for design optimization and exploration. An essential aspect in application of the design principle is the careful definition of platform layers. Platforms can be defined at several point of the design process, and some levels of abstraction are more important than others in the overall design trade-off space. In particular, the articulation point between system definition and implementation is a critical one for quality and time in an embedded system environment. For this reason, we will be concerned now with the definitions of Architecture Platform and of its Instance, from reference [2], which deals with low-level layer (hardware specifications), but it brings us to the most important definition of Programmer’s Model or Application Program Interface (API). In the next chapter, where we consider the Network Platform, we will see how to generalize that definition to NAPI (Network API, also called NPI).
2.5.2
(Micro-) Architecture Platforms
Integrated circuits used for safety-critical embedded systems will most likely be developed as an instance of a particular (micro-) architecture platform. That is, rather than being assembled from a collection of independently developed blocks, they will be derived from a specific family of micro-architectures, possibly oriented toward a particular class of problems, that can be modified by the system developer. The elements of this family are a sort of common hardware denominator that could be shared across multiple applications. Hence, the (micro-)
Page 23
Columbus IST-2001-38314 WPBD
System Design Methodology
architecture platform concept, as a family of micro-architectures that are closely related to each other, leads to design time optimization: every element of the family can be obtained quickly by personalizing an appropriate set of parameters of the micro-architecture. For example, in an adhoc wireless sensor network environment, like the MICA2 motes which we will consider later in this deliverable, each node may be characterized by the same family of programmable processor and even the same interconnection scheme, but the memories or the transceiver radio system may be selected from a pre-designed library of components depending on the particular application or communication protocol constraints. The less constrained the platform is, more freedom a designer has in selecting an instance (choosing its parameters) and the more potential there is for optimization – if time permits. However, more constraints mean more constrained standard interface, consequently easier addition of components to the library that defines the architecture platform. Note that the basic concept is that regularity and re-use of library elements allow faster design time at the expense of some optimality. The trade-off between design time and cost and design quality has always to be kept in mind. Given that the elements of the library are re-used, there is a strong incentive to optimize them. In fact, it makes sense to offer a variation of hardware blocks with the same functionality but with implementations which differ in performance, area and power dissipation. It should be remarked that this optimization issue is closely related to the hardware implementation, so the system designer, who operates at the top of the stack, is only interested in functionality of the hardware: the details of their implementation are insignificant. Thus, we actually realize the orthogonalization of concerns we mentioned before. Architecture platforms are often characterized by the presence of programmable components, so that each platform instance, that can be derived from the architecture platform, maintains enough flexibility to support a
Columbus IST-2001-38314 WPBD
Page 24
2.5 Platform-Based Design
sufficiently wide application space. Obviously, an architecture platform instance is derived from an architecture platform by choosing a set of components from its library and/or by setting parameters of its re-configurable components. Programmability will ultimately be of various forms: software programmability is usually intended to indicate the presence of a micro-processor, DSP or any other software programmable component, while hardware programmability is intended to indicate the presence of reconfigurable logic blocks such as FPGAs, whereby logic function can be changed by appropriate software tools. Some of the new architecture platforms being offered on the market include a mix of the two into a single chip (for example, Altera and Xilinx are offering FPGA fabrics with some PowerPC, that is an embedded hard processor). Software programmability yields a more flexible solution since modifying software is in general faster and cheaper than modifying FPGA personalities. On the other hand, logic functions mapped on FPGAs can be executed orders of magnitude faster and with much less power than the corresponding implementation as a software program. Thus, the trade-off here is between flexibility and performance.
Architecture Platform Design Issues When seen from the application domain (top view), constraints that determine the architecture platform are often given in terms of performance and size. For a particular application, it is required that, to sustain a set of functions, a CPU should be able to run at least at a given speed and the memory system should be of at least a given number of bytes. Coming from the IC manufacturer space (bottom view), production and design costs imply adding platform constraints and consequently reducing the number of choices. The intersection of the two sets of constraints defines the architecture platforms that can be used for the final product: this is neither a topdown nor a bottom-up design methodology. In fact, in a pure top-down
Page 25
Columbus IST-2001-38314 WPBD
System Design Methodology
design process, application specification is the starting point for the design process. The sequence of design decisions drives the designer toward a solution that minimizes a cost function. Whereas, in a bottom-up approach, a given instance of the architecture platform is designed to support a set of different applications that are often vaguely defined. Therefore, the designer tries to maximize the number of applications of its platform instances. The ultimate goal of the new methodology is to define platforms and platform instances in close collaboration with system companies thus fully realizing the meet-in-the-middle approach. Note that, because of this process, we may have a platform instance that is over-designed for a given product; that is, the potential of the architecture is not fully exploited to implement the functionality of the final product. In several applications, the over-designed architecture has been a perfect vehicle to deliver new software products and extend the application space. Thus, it is believed that some degree of such over-design will be positive the embedded systems. To summarize, the design of an architecture platform is the result of a trade-off in a complex space that includes [2] the following aspects: • The size of the application space that can be supported by the architectures belonging to the architecture platform. This represents the flexibility of the platform; • The size of the architecture space that satisfies the constraints embodied in the architecture platform definition. This represents the degrees of freedom that architecture providers have in designing their hardware instances. Once an architecture platform has been selected, then the design process consists of exploring the remaining design space with the constraints set by the platform. These constraints cannot only be on the components themselves, but also on their communication mechanism. In addition, ap-
Columbus IST-2001-38314 WPBD
Page 26
2.5 Platform-Based Design
proaching an implementation by selecting components that satisfy the architectural constraints defining a platform, means performing a successive refinement process where details are added in a disciplined way to produce an architecture platform instance. Application developers work with an ideal architecture platform by first choosing the architectural elements they believe are the best for their purposes. Then, they must map the functionality of their application onto the platform instance. The mapping process includes hardware/software partitioning. In fact, while performing this step, designers may decide to move a function from software implementation to a dedicated hardware block. Once the partitioning and the selection of the platform instance are finalized, the designers develop the final and optimized version of the application software. Because of the market forces briefly outlined above (low cost and developing time), many implementations of a system functionality are done in software. This implies that an effective platform must offer a powerful design environment for software. Thus, there are two main concerns for an effective platform-based design: • Software development environment; • A set of tools that insulate the details of the architecture from application software. This brings us to the definition of an API platform.
2.5.3
API Platform
The concept of architecture platform by itself is not enough to achieve the level of application re-use we require. The architecture platform has to be abstracted at a level where the application software sees a high-level interface to the hardware that is called Application Program Interface (API) or
Page 27
Columbus IST-2001-38314 WPBD
System Design Methodology
Figure 2.3: Layered software structure (Source: A. Ferrari) [2] Programmer’s Model. A software layer is used to perform this abstraction (see Figure 2.3). This layer wraps the essential parts of the architecture platform [2]: • The programmable cores and the memory subsystem via a Real Time Operating System (RTOS), • The I/O subsystem via the Device Drivers, and • The network connections via the network communication subsystem. In this frame, while a programming language is the abstraction of the Instruction Set, the API is the abstraction of a set of computational resources (concurrency model provided by the RTOS) and available peripherals (Device Drivers). The API is a unique abstract representation of the architecture platform through the software layer. With such a defined API, the application software can be re-used for every platform instance. Indeed, the Programmer’s Model is a platform itself which can be called the API platform. As usual, the higher the abstraction level at which a platform is defined, the more instances it contains. For example, to share source code, we need to have the same operating system but not necessarily the same instruction set, while to share binary code, we need to add the architectural constraints that force to use the same ISA, thus greatly restricting the range of architectural choices. RTOS is responsible for scheduling of the available computing resources and of communication between them and the memory subsystem. Note that in several safety-critical embedded system applications, the available
Columbus IST-2001-38314 WPBD
Page 28
2.5 Platform-Based Design
Figure 2.4: System platform stack [2] computing resources consist of a single microprocessor, but in general one can imagine a multiple core architecture platform, where RTOS schedules software processes across different computing engines.
2.5.4
System Platform-Stack
The basic idea of system platform-stack is captured in Figure 2.4. The vertex of the two cones represents the combination of the API or Programmer’s Model and the architecture platform. A system designer maps its application into the abstract representation, which includes a family of architectures that can be chosen to optimize a proper functional (cost, efficiency, energy consumption or flexibility). Mapping of the application platform into the actual architecture platform instance in the family specified by the API can be carried out (at least in part) automatically and in a two step sequence, only if a set of appropriate software synthesis tools is available. It is clear that the synthesis tools have to be aware of the architecture features as well as of the API related with them. Then, starting from the application platform we can synthesize the API platform in a first step, eventually with a successive refinement process; after this, in a second step we can use the software layer to go from the API platform to the architecture platform. In the design space, there is an obvious trade-off between the level of abstraction of the Programmer’s Model and the number and type of the platform instances covered. In fact, remember that the more abstract the Programmer’s Model is the richer the set of platform instances is, but the more difficult is the choice of optimal architecture platform instance and automatically mapping on this. Hence, one can envision a number of system platform stacks which will be handled with somewhat different abstractions and tools. In fact, later in this deliverable we will see the Network
Page 29
Columbus IST-2001-38314 WPBD
System Design Methodology
Platform, which is a generalization of this framework and that is a typical example of the fractal nature of the design methodology: the design problem repeats itself at every level of the design hierarchy. Generalizing the process, the design is seen mainly as a process of providing abstraction views like in a database management system, where each user could see only a part of data there are stored, and it could obtain any kind of data aggregation according to its needs. Therefore, an API platform is an abstraction layer above some more complex systems, which could be used for designing at a higher level, forgetting that there are several implementation details. Following this model, a structural view of the design is abstracted into the API model that provides the basis for all design processes that rest upon this layer of abstraction. To choose the right architecture platform, we have to export at the API level an execution model of such an architecture platform that estimates performance of the lower level. On the other hand, we can pass constraints from higher levels of abstraction down to lower ones, in order to continuing the refinement process and, hence, satisfying the original design constraints. With both constraints and estimates, we may also use some cost function to select a solution among the feasible ones. In summary, the system platform stack is a comprehensive model which includes the view of platforms from both the application and the implementation points of view. It is the vertex of the two cones in Figure 2.4. Note that the system platform effectively decouples the application development process (the upper triangle) from the architecture implementation process (the lower triangle).
2.5.5
A Formal Interpretation of Platform-based Design
As we have seen, an essential component of PBD is the successive refinement process that takes from the higher layers of abstractions to the final implementation. The refinement process is interpreted as the concretiza-
Columbus IST-2001-38314 WPBD
Page 30
2.5 Platform-Based Design
tion of a function in terms of the elements of an architecture. The process of design consists of evaluating the performance of different kinds of architectures by mapping the functionality onto its different elements. The implementation is then chosen on the basis of some cost function. In the sequel, we will cast the successive refinement design flow in a formal framework described in terms of abstract algebra. This section is not self-contained in the sense that some of the terminology typical of abstract algebra is not defined. The theory background is way beyond the scope of this report. We refer the reader to [10] as the main source of the results presented here that can be nevertheless intuitively grasped.
Agent Algebras Our formalization of the platform-based design methodology is based on the framework of Agent Algebra [10]. Informally, an agent algebra Q is composed of a domain D that contains the agents under study for the algebra, and of certain operators that formalize the most common operations of the models of computation used in embedded system design. Different models of computation are constructed by providing different definitions for the domain of agents and the operators. The algebra also includes a master alphabet A that is used as the universe of “signals” that agents use to communicate with other agents. Each agent in the algebra is associated to the alphabet A ⊆ A of the signals it uses. The operators of the algebra are partial functions on the domain D and have an intuitive correspondence with those of most models of concurrent systems. The operation of renaming, which takes as argument a renaming function r on the alphabet, corresponds to the instantiation of an agent in a system. Projection corresponds to hiding a set of signals, and takes the set B of signals to be retained as a parameter. Hence it corresponds to an operation of scoping. Finally, parallel composition corresponds to the concurrent “execution” of two agents. It is possible to define other operators.
Page 31
Columbus IST-2001-38314 WPBD
System Design Methodology
We prefer to work with a limited set and add operators only when they cannot be derived from existing ones. In particular, here we will be mainly concerned with the operator of parallel composition. The operators must satisfy certain axioms that formalize their intuitive behavior and provide some general properties that we want to be true regardless of the model of computation. For example, parallel composition must be associative and commutative. The definition of the operators is otherwise unspecified, and depends on the particular agent model being considered. The notion of refinement in each model of computation is represented by adding a preorder (or a partial order) on the agents, denoted by the symbol �. The result is called an ordered agent algebra. We require that the operators in an ordered agent algebra be monotonic relative to the ordering. This is essential to apply compositional techniques. However, since these are partial functions, this requires generalizing monotonicity to partial functions. This generalization is however beyond the scope of this report. The interested reader is referred to [10] for more details. It is easy to construct an agent algebra Q to represent the interface that components expose to their environment. In this case, the set D consists of the agents of the form p = (I, O) where I ⊆ Q.A is the set of input ports of the components and O ⊆ Q.A the set of output ports. The alphabet of an agent p is simply A = I ∪ O, and we require that the set of inputs and outputs be disjoint, i.e., I ∩ O = ∅. The parallel composition p = p1 k p2 is defined only if the sets O1 and O2 are disjoint, to ensure that only one agent drives each port. When defined, a port is an output of the parallel composition if it is an output of either agent. Conversely, it is an input if it is an input of either p1 or p2 , and it is not concurrently an output of the other agent. Thus O = O1 ∪ O2 and I = (I1 ∪ I2 ) − (O1 ∪ O2 ). Given the definitions, it is clear that in this example connections are established by name. The model can be enriched with information about the nature of the
Columbus IST-2001-38314 WPBD
Page 32
2.5 Platform-Based Design
signals used by the agents. For instance, in the case of agents that describe communication topologies, signals can be distinguished between those that belong to a link, denoted by the symbol l, and those that belong to a component, denoted by the symbol n (non-link). The sets I and O of an agent p thus become sets of pairs of signals together with their type, i.e., I ⊆ {(a, t) : a ∈ Q.A ∧ t ∈ {l, n}} and similarly for the output ports. Parallel composition can also be modified so that the operation is defined only if the ports of the agents being connected are not of the same type, i.e., a link must be used to connect two regular ports. Hence, p1 k p2 is defined if and only if for all i ∈ I1 and for all o ∈ O2 , if i.a = o0 .a then i.t 6= o0 .t, and viceversa for p2 and p1 . With these definitions, it is in general not possible to derive the components from the composite. Later, we will see how this can be accomplished for a different model that we use to define architectures. There, we will also introduce non-trivial orderings of the agents. Different agent algebras can be related by means of conservative approximations. A conservative approximation from Q to Q0 is a pair Ψ = (Ψl , Ψu ), where Ψl and Ψu are functions from Q.D to Q0 .D. The first mapping is an upper bound of the agent relative to the order of the algebra: for instance, the abstract agent represents all of the possible behaviors of the agent in the more detailed domain, plus possibly some more. The second is a lower bound: the abstract agent represents only possible behaviors of the more detailed one, but possibly not all. Formally, a conservative approximations is an abstraction that maintains a precise relationship between the orders in the two agent algebras. In particular, Ψ = (Ψl , Ψu ) is a conservative approximation from Q to Q0 if and only if for all agents p and q in Q.D, Ψu (p) � Ψl (q) =⇒ p � q. Thus, when used in combination, the two mappings allow us to relate refinement verification results in the abstract domain to results in the more detailed domain. Hence, the verification can be done in Q0 , where it is pre-
Page 33
Columbus IST-2001-38314 WPBD
System Design Methodology
sumably more efficient than in Q. The conservative approximation guarantees that this will not lead to a false positive result, although false negatives are possible depending on how the approximation is chosen. The inverse of a conservative approximation provides us a formal tool to embed one model of computation into another, and corresponds to the process of refinement in a platform-based design methodology. To define the inverse Ψinv of an approximation, we investigate whether there are agents in Q.D that are represented exactly by Ψu and Ψl , rather than just being bounded. We do so by only considering those agents p for which Ψl (p) and Ψu (p) have the same value p0 . Intuitively, p0 represents p exactly in this case, and we therefore define Ψinv (p0 ) = p. If Ψl (p) 6= Ψu (p), then p is not represented exactly in Q0 . In this case, p is not in the image of Ψinv . Thus, for p0 ∈ Q0 .D, the inverse Ψinv (p0 ) is defined and is equal to p if and only if Ψl (p) = Ψu (p) = p0 . If the algebra Q is partially ordered (as opposed to preordered), the inverse of the conservative approximation is uniquely determined. Otherwise, a choice may be possible among order equivalent agents. In all cases, however, because of the defining properties of a conservative approximation, Ψinv is one-to-one, monotonic, and inverse of both Ψl and Ψu . Assume now that for an agent p, Ψinv (Ψl (p)) and Ψinv (Ψu (p)) are both defined, It is easy to show that Ψinv (Ψl (p)) � p � Ψinv (Ψu (p)). This fact makes precise the intuition that Ψl (p) and Ψu (p) represent a lower and an upper bound of p, respectively.
Platform-Based Design Theory We can us agent algebras to describe formally the process of successive refinement in a platform-based design methodology. Both the function and the platform can be represented at different levels of abstraction. For example, a platform may use a generic communication structure that includes point-to-point connections for all elements, and un-
Columbus IST-2001-38314 WPBD
Page 34
2.5 Platform-Based Design
limited bandwidth. On a more accurate level, the communication structure may be described as a bus with a particular arbitration policy and limited bandwidth. Similarly, the functionality could be described as the interconnection of agents that communicate through either unbounded (more abstract) or bounded (more concrete) queues. We use three distinct domains of agents to characterize the process of mapping and performance evaluation, The first two are used to represent the platform and the function, while the third, called the common semantic domain, is an intermediate domain that is used to map the function onto a platform instance. A platform, depicted in Fig. 2.6 on the right, corresponds to the implementation search space. A platform consists of a set of elements, called the library elements, and of composition rules that define their admissible topologies of interconnection. To obtain an appropriate domain of agents to model a platform, we start from the set of library elements D0 . The domain of agents D is then constructed as the closure of D0 under the operation of parallel composition. In other words, we construct all the topologies that are admissible by the composition rules, and add them to the set of agents in the algebra. Each element of the architecture platform is called a platform instance. Performance evaluation usually requires that the elements of a platform include information regarding their internal structure. Thus, an algebra such as the typed IO agent algebra described above is not suitable for this purpose, since composition does not retain the structure of the agent. The IO agents can, however, be used as library elements D0 . A new domain of agents D can then be constructed as follows. If p0 ∈ D0 is a library element, we include the symbol p0 in the set of agents Q.D. We then close the set D under the operation of parallel composition. However, we represent a composition p = p1 k p2 in Q as the sequence of symbols p1 k p2 . By doing so, we retain the structure of the composite, since all the previous
Page 35
Columbus IST-2001-38314 WPBD
System Design Methodology
composition steps are recorded in the representation. We call this process a platform closure. More formally, the platform closure of the elements D0 with composition operator k is the algebra with domain D = {p : p ∈ D0 } ∪ {p1 k p2 : p1 ∈ D ∧ p2 ∈ D}
(2.1)
where p1 k p2 is defined if and only if it can be obtained as a legal composition of agents in D0 . The construction outlined above is general, and can be applied to building several different platforms. The result is similar to a term algebra with the “constants” in D0 and the operation of composition. Unlike a term algebra, however, our composition is subject to the constraints of the composition rules. For example an “architecture” platform may provide only one instance of a particular processor. In that case, topologies that use two ore more instances are ruled out. In addition, the final algebra must be taken up to the equivalence induced by the required properties of the operators. For example, since parallel composition must be commutative, p1 k p2 should not be distinguished from p2 k p1 . This can be accomplished by taking the appropriate quotient relative to the equivalence relation. The details are outside the scope of this report.
Figure 2.5: Mapping of function and architecture On the other hand, the function, depicted in Fig. 2.6 on the left, is represented in an agent algebra called the specification domain. Here the desired function may be represented denotationally, as the collective behavior of a composition of agents, or may retain its structure in terms of a particular topology of simpler functions. The denotational representation is typically used at the beginning of the platform-based design process, when no information on the structure of the implementation is available. Conversely, after the first mapping, the subsequent refinement steps are started from the mapped platform instance, which is taken as the specification. Thus, a common semantic domain, described below, is used as the specification do-
Columbus IST-2001-38314 WPBD
Page 36
2.5 Platform-Based Design
main. However, contrary to the mapping process that is used to select one particular instance among several, when viewed as a representation of a function the mapped instance is a specification, and it is therefore fixed. The function and the platform come together in an intermediate representation, called the common semantic domain. This domain plays the role of a common refinement and is used to combine the properties of both the platform and the specification domain that are relevant for the mapping process. In fact, the function platform may be too abstract to talk about the performance indices that are characteristic of the more concrete architecture, while at the same time the architecture platform is a mere composition of components, without a notion of behavior. The domains are related through conservative approximations. In particular, we assume that the inverse of the conservative approximation is defined at the function that we wish to evaluate. The function therefore is mapped onto the common semantic domain as shown in Fig. 2.6. This mapping also includes all the refinements of the function that are consistent with the performance constraints, which can be interpreted in the semantic domain.
Figure 2.6: Mapping of function and architecture If the platform includes programmable elements, the correspondence between the platform and the common semantic domain is typically more complex. In that case, each platform instance may be used to implement a variety of functions, or behaviors. Each of these functions is in turn represented as one agent in the common semantic domain. A platform instance is therefore projected onto the common semantic domain by considering the collection of the agents that can be implemented by the particular instance. These, too, can be organized as a refinement hierarchy, since the same function could be implemented using different algorithms and employing different resources even within a particular platform instance. This projection, represented by the rays that originate from the platform in
Page 37
Columbus IST-2001-38314 WPBD
System Design Methodology
Fig. 2.6, may or may not have a greatest element. If it does, the greatest element represents the non-deterministic choice of any of the functions that are implementable by the instance. An architecture and a specification domain may be related using different common semantic domains, and under different notions of refinement. The choice of common semantic domain is particularly important. The agents in the common refinement must in fact be detailed enough to represent the performance values of interest in choosing a particular platform instance, and a particular realization (via programmability) of the instance. However, if the representation is too detailed, the correspondence between the platform instance and its realizations may be impractical to compute. This correspondence is therefore usually obtained by estimation techniques, rather than by analytical methods. The common semantic domain is partitioned into four different areas. We are interested in the intersection of the refinements of the function and of the functions that are implementable by the platform instance. This area is marked “Admissible Refinements” in Fig. 2.6. In fact, the agents that refine the function, but do not refine the architecture, are possible implementations that are not supported by the platform instance. The agents that refine the platform instance, but not the function, are possible behaviors of the architecture that are either inconsistent with the function (they do something else), or they do not meet the performance constraints. The rest of the agents that are not in the image of any of the maps correspond to behaviors that are inconsistent with the function and are not implementable by the chosen platform instance. Among all the possible implementations, one must be chosen as the function to be used for the next refinement step. Each of the admissible refinements encodes a particular mapping of the components of the function onto the services offered by the selected platform instance. These can often be seen as the covering of the function through the elements of the platform
Columbus IST-2001-38314 WPBD
Page 38
2.5 Platform-Based Design
library. Of all those agents, we are usually interested in the ones that are closer to the greatest element, as those implementations more likely offer the most flexibility when the same refinement process is iterated to descend to an even more concrete level of abstraction. In addition, several different platform instances may be considered to search among the different topologies and available resources and services. Once a suitable implementation has been chosen (by possibly considering different platform instances), the same refinement process is iterated to descend to an even more concrete level of abstraction. The new function is thus the intersection of the behavior of the original function and the structure imposed by the platform. The process continues recursively at increasingly detailed levels of abstraction to come to the final implementation.
Page 39
Columbus IST-2001-38314 WPBD
Chapter 3
The Platform-Based-Design Flow (Deliverable DDF1) This chapter is divided in three sections. The first section describes a simplified logic synthesis flow which highlights the key aspects of platformbased design. The second section motivates the need of a recursive design paradigm and applies platform-based design in the context of multimedia designs. The last section shows the implementation of the multimedia design flow in the Metropolis framework. This chapter serves as an introduction and a general framework for the following chapters where we focus on a set of important case studies.
3.1
Logic Synthesis Flow as an Example of a Platformbased Design Flow
Section 2.5.5 formalizes the platform-based design principle using an algebraic approach. It clearly shows that the platform-based design methodology is a recursive paradigm where the action of mapping a function onto
Columbus IST-2001-38314 WPBD
Page 40
3.1 Logic Synthesis Flow as an Example of a Platform-based Design Flow
an architecture generates a new function described at a lower level of abstraction and therefore more detailed than the original one. A design process typically starts with a denotational description of the function that we want to implement, plus a set of constraints that the implementation has to satisfy. Filtering a signal x(t), for instance, can be denotationally described as x(t) ⊗ h(t), namely the convolution of the signal with the filter impulse response h(t). Design constraints are usually specified as propositional formulas over the system quantities. In the case of filtering, for example, we can specify a lower bound on the off-band signal attenuation. Constraints specified at this level of abstraction are propagated down to all subsequent levels, until the implementation level is reached. While constraints are propagated in a top-down fashion, performances are abstracted bottom-up. Performance abstraction is the process of hiding details that are not relevant for the level of abstraction under consideration. In fact, each level of abstraction focuses on a particular design choice on which only few quantities have impact. Abstraction of quantities that are not relevant is essential for speeding up the design space exploration. In this section we focus on one step of the design flow characterized by a function, an architecture and the mapping of the former onto the latter. We use a simplified logic synthesis flow as a representative example. Figure 3.1 shows the design process. The function is described in the register transfer level (RTL) domain. In this domain a function is described as interconnection of combinational logic blocks communicating through registers. Furthermore, each combinational block takes zero time to compute its logic function. The platform is composed of all possible logic functions that can be implemented on a chip using standard cells technology. The library of components, from which the platform is built up, contains pre-characterized logic functions that are usually custom designed to achieve high performance. Each library element is characterized by the its logic function, per-
Page 41
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
Figure 3.1: Platform based representation of a simplified logic synthesis flow formance, power consumption and area. An OR logic gate, for instance has a truth table, gate delay, power consumption associated with it. A common semantic domain for the RTL functional description and the standard cell platform is the domain of all circuits built out of 2-input NAND gates. In fact, every logic function can be expressed using NAND gates only. Mapping an RTL function onto the standard cell platform can be done in the following way. First, we analyze the RTL description, express it as in mathematical terms using Boolean algebra, reduce the complexity of the Boolean expression and for each combinational block express its function using 2-inputs NAND gates. Secondly, we express each library cell logic function using the same elementary gate. Finally, the problem reduces to a minimum cost covering of the original function with the library elements where the cost function can be power or minimum slack. The covering problem is an optimization problem subject to the constraints coming from the original specification. Typical constraints that are associated with the functional specification are clock speed, inputs arrival time and output required time. After the covering algorithm has finished, those constraints must be checked (using timing analysis). If they are not
Columbus IST-2001-38314 WPBD
Page 42
3.2 Levels of Abstractions in Multimedia System Design
met, the designer has two choices: going back and modifying the RTL description by using a different block partitioning, or moving the covering algorithm out of the local minima. The resulting netlist is an interconnection of standard cells that is indeed a new function F 0 . This function represents a refinement of the original one described at a much higher level of abstraction. F 0 is the new specification for the next design step whose platform library is composed of transistors and wires. Original constraints are propagated further down and must be satisfied by the transistor level implementation. The simple design process described above is very general. Once a common semantic domain has been defined so that both the function and the platform elements can be expressed using a common mathematical formalism, design exploration reduces to a covering problem. The covering algorithm has to minimize a cost function which is the sum of the costs of each platform component that has been used during the covering. The entire optimization problem is subject to the original constraints.
3.2
Levels of Abstractions in Multimedia System Design
Going from the denotational description of a function down to its implementation is a very hard problem. The number of possible design choices makes the design space too large to be explored efficiently. The big design gap can be subdivided into smaller steps by introducing a stack of platforms, each dedicated to the exploration of the design space along few directions (figure 3.2). When using a platform-based design methodology the first important step is defining those level of abstractions. Consider, for instance, the case of multimedia systems design as shown in figure 3.2. Starting form the denotational description of the function F the first important decision is to se-
Page 43
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
Figure 3.2: Platform stack for multimedia designs lect a suited platform (that a this level of abstraction is usually referred to as a model of computation) to describe F . The only property of interest at this level is correctness. Kahn process networks (KPN) is a convenient model of computation usually adopted as the first platform for modeling multimedia systems. The platform components are processes running on their own threads and communicating through unbounded FIFOs with blocking read and non-blocking write semantics. Mapping F onto the Kahn process networks platform implies re-expressing the denotational algorithm as interconnection of concurrent processes and unbounded FIFOs. For instance, an FIR filter can be described by interconnecting adders and multipliers together. At this level of abstraction we can check if our algorithm is correct without caring about deadlocks due to resource limitations like FIFOs boundedness. Also, since processes are totally concurrent and write is non-blocking, processes don’t have to competed for
Columbus IST-2001-38314 WPBD
Page 44
3.2 Levels of Abstractions in Multimedia System Design
shared resources. The designer can then explore the maximum amount of concurrency (parallelism) in the functional description without being constrained by resource limitations. However, the function is too abstract to be implemented on a real architecture which has resource limitations, e.g. memory size. The next level of abstraction is represented by the TTL (task transaction level) platform. It is still composed of processes running on their own threads, but the communication among them is implemented with bounded FIFOs. Mapping a KPN function onto a TTL platform is a simple one to one mapping that can be done by a direct refinement of each unbounded FIFO into a more complicated channel as we will see in the next section. At the TTL level of abstraction, we are concerned with memory size minimization. Each communication channel is parameterized by the token size and the maximum number of tokens it can contain. Depending on the interleaving policy between writer and reader of the same channel, buffer size can be reduced at the expense of a more frequent context switching between the two processes. Memory/switching overhead trade-off is explored at this level of abstraction. Finally the TTL description is mapped onto a real micro-architecture, for instance a single processor architecture. At this level of abstraction we are concerned with memory allocation and organization and task scheduling. Task scheduling is needed because at this level we have a computational resources limitation (only one processor in this example). A real time operating system works as an adaptation layer between the high level of concurrency of the TTL platform and the sequential operations of a single processor architecture. The result of this mapping is the implementation of the original function on a target micro-architecture that satisfies all the original constraints.
Page 45
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
3.3
Implementation of the Multimedia design flow in Metropolis
This section first introduces the Metropolis metamodel language describing its basic building blocks. Then it shows how a platform-based design flow for multimedia application is implemented using the Metropolis framework.
3.3.1
The Metropolis metamodel
The Metropolis metamodel (MMM) is a language that defines a set of building blocks. Each building block, which may be thought of as a statement of the language, has a formal semantics associated with it. The execution semantics of an interconnection of blocks is defined as the composition of the execution semantics of each single statement. MMM is not only used for describing a system but it can be used to implement entire design methods. A design method is described by the levels of abstraction and a set of tools for mapping the specification described at one level to the next level. The implementation of a design method is made possible by the following properties: • a set of basic language constructs for the description of computation, communication, synchronization and design constraints. The MMM language also provides primitives to link designs at different levels of abstraction in order to keep track of refinement relations among components. • An internal representation of the MMM programs, a set of API’s to browse the program structure and an open interface to interact with external tools.
Columbus IST-2001-38314 WPBD
Page 46
3.3 Implementation of the Multimedia design flow in Metropolis
Semantics of MMM statements is defined in terms of action automata. Consider the simple assignment y = x + 1. Figure 3.3.
Figure 3.3: Action automata for the assignment expression y = x + 1 which contains the subexpression x + 1. MMM defines statements, function calls, functions arguments and toplevel expressions as actions. Also an event is the beginning or ending of an action. For instance, in our example there are two actions: the assignment y = expr and the sum x + 1 (which is the right hand side of the expression). An action automaton is a state machine where state transitions are labeled with events. In the assignment example, for instance, beginning of assignment (Beg(y = x + 1)) is an event which brings the automaton in the initial state. Execution of the assignment statement then proceeds with the beginning of the sum, then the end of the sum and finally the end of the assignment. Variable y takes the value of expression x + 1. If, in any of the automaton state, there is an access to either variables x or y, a transition labeled with write v (where v is the variable) is taken leading to a final value for y which is undetermined (denoted with the special value any). MMM specifies building blocks for computation, communication and coordination which are respectively called processes, media and quantities. A process runs on its own thread which is a sequential stream of statements. Its action automaton is the composition of all action automata of
Page 47
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
its statements. Processes can have internal state variables, parameters and ports. A port has a type which is an interface (in the same sense of Java programming). It means that a process can use the services declared by the interface. Processes communicate through media. A medium is a passive object implementing the services (interface) that a process accesses through its ports. A media does not have a thread of execution, it can be rather thought of as a set of functions that are called by processes. A medium, then, inherits the thread of the caller process. Each process executes a stream of actions and hence generates a sequence of events. Since processes run concurrently, an execution of an MMM program is defined as a sequence of event vectors containing one event for each process. Finally, MMM defines quantity managers to enforce a specific scheduling of events. Using quantity manager it is possible to force a process to execute a nop event blocking its execution. Processes issue requests to annotate an event with a quantity (e.g. time, power etc.) to quantity managers that first execute their scheduling algorithms and then decide which event can be annotate/executed and finally satisfy those requests. A special statement has been added to MMM language for describing access synchronization to shared resources. Consider, for instance, the case where a media is accessed by two processes that use the same variable v stored in the media itself. Since processes run concurrently, we should prevent simultaneous access to v. MMM defines await statement for synchronizing threads. await { < guard ; > ; > )
[statements;] > ;
Columbus IST-2001-38314 WPBD
Page 48
3.3 Implementation of the Multimedia design flow in Metropolis
> )
[statements;] >> } Semantics of this statement can be informally described as follows. Each statements compound is a critical section which is executed only if its guard evaluates to true and if no other process is accessing the interfaces of the test list. When a critical section is entered by a process, all the interface in the set list are blocked in order to prevent other process to access the same interface.
3.3.2
Functional Description
The application example that we consider here is called PiP. It is the core of a digital set-top-box with picture-in-picture capabilities. The set-top-box user has the possibility of watching a main channel and having at the same time a secondary small picture, inside the main picture, showing another channel. The user can tune parameters like position and size of the picture, frame color, frame size for both the main and secondary channels. The functional block diagram is shown in Fig. 3.3.2. The transport stream is decoded by TS DEMUX. The decoded stream is then passed to PES PARSER that selects the channel to visualize, depending on the user choice. Two streams can be chosen: one for the main channel and the other for the secondary picture. Each channel is then decoded by MPEG DECODER. The secondary channel is then re-sized. The RESIZE block takes user parameters to set the picture size, frame size and color. Finally the JUGGLER mixes the two decoded streams, while setting also the position of the secondary channel on the main one. Each block is a hierarchical netlist for a total of 47 process instances and 294 channel instances. The latter number is extremely important since this kind of applications is in general communication bounded.
Page 49
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
PIP
USRCONTROL main_channel
pixelsout
pip_position_in
linesout window_params
finfo MPEG Y_d, Y_i U_d, U_i V_d, V_i
es1 pes pid TS_DEMUX
finfo RESIZE Y_d, Y_i U_d, U_i V_d, V_i Y_d, Y_i U_d, U_i V_d, V_i
PES_PARSER
err JUGGLER
es2 Sinfo, finfo MPEG Y_d, Y_i U_d, U_i V_d, V_i
Figure 3.4: Block diagram representation of the picture-in-picture example
A natural domain for the functional description of multimedia systems is Non-deterministic Kahn Process Networks (NKPN). One of its semantics definitions and implementations was developed by Philips and known as the YAPI (Y-chart Application Programming Interface) model of computation. The YAPI platform is implemented in the Metropolis meta-model as a set of three elements: the medium type yapichannel, the process type yapiprocess and the netlist type yapinetlist. yapichannels are unbounded FIFOs implementing a non-blocking write, blocking read semantics. Communication channels implement two functions p.read(D,n), p.write(D,n) for reading writing data. Also each process can ask the FIFOs state which is a way of implementing non-determinism. An example of a simple producer/consumer system with its meta-model code is shown in figure 3.5. All the netlist components are defined by extension of the yapi library com-
Columbus IST-2001-38314 WPBD
Page 50
3.3 Implementation of the Multimedia design flow in Metropolis
ponents. The designer specifies the components behavior by overloading the execute function of the yapiprocess class. Typically this function will include and infinite loop and a sequence of read and write calls.
Figure 3.5: ht The YAPI network is refined into a more detailed model that is able to show the transactions between reader and writer of each channel. The task-transaction-level (TTL) platform is also provided as a library domain in Metropolis. Central to this platform is the definition of a finite length buffer and a set of APIs to access it. A ttlmedium implements four methods: claim space, release data, claim data, release space. Their meaning are respectively to check if there is enough space in the FIFO for writing, to actually write data, to check if there are sufficient data for reading and finally to release space previously occupied by tokens received by the reader. In order to refine a yapichannel into a ttlmedium, an interface hierarchical medium (a netlist) must be defined. It has to implement the yapi input and output interfaces using the services offered by a ttlmedium. The complete netlist that is used to refine a yapichannel is shown in figure 3.3.2.
Page 51
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
Figure 3.6: Structure of the netlist used to refine a yapichannel using a bounded FIFO ttlmedium
Yapi2TTL and TTL2Yapi are two media that implement the yapi API in terms of the lower lever TTL API. A yapi write is broken into a sequence of TTL claim space and release data calls. In order for a write to be completed on a finite length buffer possibly smaller than the data size of a single read, tokens must be written and read in a ping-pong fashion. This handshake protocol is implemented using a shared synchronization medium called rdwrth. The designer can explore a set of refinement scenarios by changing a few parameters, such as the FIFO length (number of tokens), the token size, and also the handshake protocol. To refine a YAPI channel into a ttlrefyapi netlist, a special metropolis
Columbus IST-2001-38314 WPBD
Page 52
3.3 Implementation of the Multimedia design flow in Metropolis
Figure 3.7: Block diagram of the architecture platform netlist in Metropolis statement refine is called which relates the two level of abstractions.
3.3.3
Architectural Platform
Architectural platforms offer a set of services to implement the algorithms described in the functional part. Depending on the level of abstraction, services may have different granularities. At the lowest level, for instance, the services provided to implement a function are instructions and logic gates. In this example we decided to model architectures at a high level of abstraction, in order to speed up simulation-based analysis, and enable formal verification to be carried out. The architecture structure is depicted in figure 3.3.3. The essential elements that compose the architecture are shown in the scheduled netlist. A number of software tasks (Ti in the figure) share a CPU under control of a
Page 53
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
Real-Time Operating System, which simulates concurrency between them. There is one main memory, which is accessible through the bus. Tasks implement services which have to be considered as the building blocks to implement the functional specification. The implementation could be just a model for the performances of software library functions that are provided as Intellectual Property blocks (IPs) by the platform developer. Consider for instance the case in which a digital filter function is provided as a part of a software IP library. Then one of the functions that the library task implements is called filter. The parameter of this function could be the number of samples to process (assuming that the number of taps is fixed). The task will uses services provided by the bus and by the real time operating system. Since we do not need to model the functionality, which we assume to be modeled in the functional netlist, we just call an execute service provided by the CPU. This service models only the fact that the filter requires a certain number of CPU cycles in order to perform its computation. In our case, as developers of the models of the YAPI and TTL platforms, we decided to offer services that match the TTL services described in 3.3.2. Each task implements the TTL primitives claim space, release data, claim data, release space. These methods are implemented using services provided by the CPU and the real time operating system. In the standalone model of our platform each task non-deterministically executes one of its services, while charging for its cost. An example of a task is shown in figure 3.8. To annotate quantities and to schedule task, the architectural components issue requests to the quantity managers that grant requests matching the scheduling constraints. When a task asks for a service, the end event of the service will be annotated with a time that takes into account the cpu time, bus access time and bus memory time. Figure 3.9 shows how the annotation process takes place. In this simple example, a task requests to lock a mutex. To model the request overhead,
Columbus IST-2001-38314 WPBD
Page 54
3.3 Implementation of the Multimedia design flow in Metropolis
Figure 3.8: Example of task the real time operating system requests a number of cpu cycles equal to the overhead. Then a request is issued to the mutex quantity manager. The connection between any components and quantity managers has always to go through a special media called statemedia (which is denoted as TaskToQauntity in figure 3.9. After the request is issued, the task is blocked until a scheduling decision is taken by the quantity managers. A main resolution algorithm calls the scheduling algorithms of all quantity managers in a user-defined order until all quantity managers agree on a common scheduling decision. After the decision is taken, the control goes back to the tasks.
3.3.4
Mapping Strategy
Mapping of function on the architecture is done by intersection of the possible events on both sides. Intersection is implemented by a synchronization statement synch(e1,e2) whose semantics is that those events have to be exe-
Page 55
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
Figure 3.9: Graphical representation of the architecture execution semantics
cuted in the same simulation step. It also means that they will be annotated with the same quantities. Synchronization of the two netlist achieve the net result of mapping the function onto the architecture. This step is a common refinement since the non-determinism of the architecture is restricted by the synchronization and at the same time the function will be described using architectural services and annotated with actual quantities. Figure 3.3.4 shows a sketch of the code that implements the mapping. As mentioned in section 3.3.2, communication plays a central role in this kind of application. A particular attention is paid to the ttlmedium netlist, and in particular to the Yapi2TTL and TTL2Yapi media. During the mapping, important parameters like queue size, queue allocation etc. are specified.
Columbus IST-2001-38314 WPBD
Page 56
3.3 Implementation of the Multimedia design flow in Metropolis
Figure 3.10: Part of the code that implements the mapping The mapping netlist constructor takes three main sets of parameters: • The function netlist scenario (explained in section 3.3.2). • The architectural parameters, such as the CPU speed, the scheduler type, the scheduler overhead and so on. • Mapping information, such as tasks priorities, task identifiers, memory mapping information and so on. After both function netlist and architecture netlist are instantiated, configured and added to the mapping netlist, designers (or, in the future, estimation and mapping tools) must relate them by binding functions to architectural services. Binding is done using linear temporal logic constraints defined in the mapping netlist. An example of such constraints is shown in figure 3.3.4. Here, process writer is the process in function netlist that calls the method release data of the bounded FIFO in the ttlmedium netlist, while task writer is a task in the architecture netlist to which we want to assign the functional process. The task writer task offers the architectural implementation of release data as a service. The formula states that the begin event of function release data of process process writer in the functional netlist has to be “synchronized” with the begin event of the release data implementation of task task writer in the architecture netlist. It also maps the memory space based on the information stored by the designer in the Ttlmap class.
Page 57
Columbus IST-2001-38314 WPBD
The Platform-Based-Design Flow (Deliverable DDF1)
A similar formula is written for the end event of the same function. The two LTL formulas will force the two netlists to proceed concurrently and in a synchronized fashion. In the particular example of release data, the end event in the function part cannot happen if the corresponding end event does not happen in the architecture part, which in turn can happen only if the CPU is assigned to the task implementing the function.
Columbus IST-2001-38314 WPBD
Page 58
Chapter 4
Platform-based Design for Wireless Ad-hoc Sensors-Network According to the previous chapter, the Platform-Based Design paradigm can be applied by including the formalization of abstraction levels higher than the API Platform. In particular, this approach can be applied to wireless ad hoc sensor networks. The use of PBD in this context is also useful to define layers of abstraction that can be used to identify standards that enable the use of this fairly new technology. We first begin by discussing the applications and the challenges for AWSNs. Then we move to the definition of the abstraction layers and we discuss a potential standard for the application interface. Finally we develop the PBD paradigm to propose a flow for the design of an AWSN.
4.1
Introduction
Ad-hoc Wireless Sensor Networks (AWSNs) are an essential factor in the implementation of the ”ambient intelligence” paradigm, which envisions
Page 59
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
smart environments aiding humans to perform their daily tasks in a nonintrusive way [43]. The wide deployment of sensor networks will also dramatically change the operational models of traditional businesses in application domains such as home/office automation [44], power delivery [45], and natural environment control [46]. The potential applications of AWSNs can be distinguished between those that monitor and those that control the environment in which they are embedded. Monitoring applications gather the values of some parameters of the environment, process them, and report the outcome to external users. Control applications, in addition to monitoring, influence the environment so that it achieves a required behavior. Both types of applications require the deployment of sensor networks with a large number of nodes that are able to capture different physical phenomena (sensors), to make control decisions (controllers), and to act on the environment (actuators). The design problem is certainly challenging: • the nodes of these networks fulfill their data gathering and control functionality working in a cooperative way; hence, inter-node communication, mostly over RF links, plays an essential role • the requirement that the network operation should continue for very long periods of time without human intervention makes low energy consumption of paramount importance • to meet the stringent power, cost, size and reliability requirements, the design of sensor networks needs optimizations throughout all the steps of the design process, including application software, the layers of the communication protocol stack and the hardware platform Currently, AWSN designs are rather ad-hoc and tailored to the specific application both in the choice of the network protocols and in the implementation platform. Today, it is virtually impossible to start developing applications without the previous selection of a specific, integrated hardware/software platform. Coupling applications with specific hardware so-
Columbus IST-2001-38314 WPBD
Page 60
4.2 A Standard for the Development of Implementation Independent Applications
lutions slows down the practical deployment of sensor networks: potential users hesitate to invest in developing applications that are intrinsically bound to specific hardware platforms available today.
4.2
A Standard for the Development of Implementation Independent Applications
To unleash the power of AWSNs, standards are needed that favor • the incremental integration of heterogeneous nodes and • the development of applications independent of the implementation platforms. To address the first concern, several efforts have been recently launched to standardize communication protocols among sensor network nodes. The best known standards are BACnet and LonWorks, developed for building automation [44]. They are geared towards well-defined application areas, and are built on top of specific network structures. Hence, they are not well suited for many sensor network applications. ZigBee [48] defines an open standard for low-power wireless networking of monitoring and control devices. It works in cooperation with IEEE 802.15.4 [47], which focuses on the lower protocol layers (physical and MAC). ZigBee defines the upper layers of the protocol stack, from network to application, including application profiles. Yet, it is our belief that efforts, like Zigbee, created in a bottom-up fashion do not fully address the essential issue: how to allow interoperability between the multitudes of sensor network operational models that are bound to emerge. In fact, different application scenarios lead to different requirements in terms of data throughput and latency, quality-of-service, use of computation and communication resources, and network heterogeneity. These requirements ultimately result in different solutions in network topology, protocols, computational platforms, and air interfaces.
Page 61
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
The second concern has been partially addressed in the automation and manufacturing community where networks of sensors (mostly wired) have been widely deployed. To achieve interoperability between different manufacturers the IEEE 1451.2 [49] standardizes both the key sensors (and actuators) parameters and their interface with the units that read their measures (or set their values). In particular, the standard defines the physical interface between the Smart Transducer Interface Module (STIM), which includes one or more transducers, and the Transducer Electronic Data Sheet (TEDS) containing the list of their relevant parameters, and the Network Capable Application Processor (NCAP), which controls the access to the STIM. Realizing that the present efforts are lacking generality and, to a certain degree, rigor, we propose in this paper an approach for the support of true interoperability between different applications as well as between different implementation platforms. We advocate a top-down approach similar to the one adopted very successfully by the Internet community and propose a universal application interface, which allows programmers to develop applications without having to know unnecessary details of the underlying communication platform, such as air interface and network topology. Hence, we define a standard set of services and interface primitives (called the Sensor Network Services Platform or SNSP) to be made available to an application programmer independently on their implementation on any present and future sensor network platform. Furthermore, we separate the virtual platform defined by the logical specification of the SNSP services from the physical platform (called the Sensor Network Implementation Platform or SNIP) that implements it and determines the quality and cost of the services. As the definition of sockets in the Internet has made the use of communication services independent of the underlying protocol stack, communication medium and even operating system, the application interface we
Columbus IST-2001-38314 WPBD
Page 62
4.2 A Standard for the Development of Implementation Independent Applications
propose identifies an abstraction that is offered to any sensor network application and supported by any sensor network platform. Yet, while similar in concept, the application interface needed for sensor networks is fundamentally different from the one defined in the Internet space. In the latter, a seamless set-up, use, and removal of reliable end-to-end communication links between applications at remote locations are the primary concern. On the other hand, sensor network applications require communication services to support queries and commands [50] among the three essential components of the network (sensor, monitor/controller, and actuator), and need also other services for resource management, time synchronization, locationing and dynamic network management.
TinyDB [51] is the existing approach closest to our effort. It views a sensor network as a distributed database and defines an application-level abstraction based on the Query/Command paradigm to issue declarative queries. However, its main goal is to define the interface and an implementation of a specific service, the query service. Hence, the TinyDB abstraction lacks of several auxiliary services needed in many sensor network applications. In addition, several decisions made as for the service description seem to have been driven by implementation considerations.
This section is structured as follows. First, we introduce the functional components of a wireless sensor network and create a framework in which we can define the services offered by the distributed Service Platform. Next, we present the services offered by the SNSP, starting from the essential Query/Command Service. A brief discussion of some auxiliary services such as locationing, timing, and concept repository follows. The section concludes presenting the Sensor Network Implementation Platform, and giving some perspectives.
Page 63
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
4.2.1
Ad-hoc Wireless Sensor Networks - Functional Architecture
The functionality of an AWSN is best captured as a set of distributed compute functions (typically called controllers or monitors, given that the most applications are either control or monitor oriented), cooperating to achieve a set of common goals. AWSNs interact with the Environment in the form of spatially distributed measurements and actuations (Figure 4.1a). The interactions with the environment are accomplished via an array of sensors and actuators, interacting with the controllers via a communication network (Figure 4.1b). The idea behind this paper is to formalize and abstract the interaction and the communications between the Application and the distributed sensors and actuators through the SNSP and its Application Interface.
The Application An AWSN Application consists of a collection of cooperating algorithms (which we call controllers) designed to achieve a set of common goals, aided by interactions with the Environment through distributed measurements and actuations. Controllers are components of AWSNs that read the state of the environment, process the information and report it or apply a control law to decide how to set the state of the environment. A controller is characterized by its desired behavior, its input and output variables, the control algorithm and the model of the environment. In addition, to ensure proper operation a controller places some constraints on parameters expressing the quality of the input data such as timeliness, accuracy and reliability.
The Sensor Network Services Platform (SNSP) The Sensor Network Services Platform (SNSP) decomposes and refines the interaction between controllers and the Environment and among controllers
Columbus IST-2001-38314 WPBD
Page 64
4.2 A Standard for the Development of Implementation Independent Applications
Figure 4.1: Functional model of an AWSN as a set of controllers (a) interacting with the environment and among each other; (b) interacting with the environment through a set of spatially distributed sensors and actuators; (c) interacting with the environment through a unified Application Interface (AI). Observe that interactions between the controllers themselves are now supported through the same paradigm.
Page 65
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
into a set of interactions between control, sensor, and actuation functions. The services that the SNSP offers the Application are used directly by the controllers whenever they interact among each other or with the Environment. This approach abstracts away the details of the communication mechanisms, and allows the Application to be designed independently on how exactly the interaction with the environment is accomplished (Figure 4.1c). The Application Interface (AI) is the set of primitives that are used by the Application to access the SNSP services. The SNSP is a collection of algorithms (e.g. location and synchronization), communication protocols (e.g. routing, MAC), data processing functions (e.g. aggregation), I/O functions (sensor, actuation). The core of the SNSP is formed by: • Query Service (QS) (controllers get information from other components) • Command Service (CS) (controllers set the state of other components) In addition, the SNSP should provide at least the following supporting services, essential to the correct operation of most sensor network applications and the ad- hoc nature of the network: • Timing Service (TSS) (components agree on a common time) • Location Service (LS) (components learn their location) • Concept Repository Service (CRS) (components agree on a common definition of the concepts during the network operation and maintain a repository of the capabilities of the deployed system) This is not an exhaustive list and more services can be built on top of these basic ones.
Columbus IST-2001-38314 WPBD
Page 66
4.2 A Standard for the Development of Implementation Independent Applications
Sensors and Actuators A sensor is a component that measures the state of the Environment. We identify two types of sensors: 1. Simple sensors: devices that directly map a physical quantity into a data value and provide the measure upon request. Devices that measure physical parameters, such as temperature, sound, and light, as well as input devices such as keyboards or microphones that allow external users to enter data or set parameters are examples of simple sensors. 2. Virtual sensors: components that overall look like sensors in the sense that they provide data upon an external request. Virtual sensors are defined by the list of parameters that can be read and by the primitives that are used for reading them. Examples of virtual sensors are • A sensor that provides an indirect measure of a certain environment condition by combining one or more sensing functions with processing (e.g., transformation, compression, aggregation). • A controller when it is queried for the value of one of its parameters. • An external network providing data through gateways. Let us consider a sensor network accessing an external information service provided by a global network (such as, for instance, weather forecasts or energy prices available on an Internet web-server). External services are accessed through a gateway that interfaces the sensor network with the global network. Through the gateway, the global network appears to the rest of the sensor network as a virtual sensor or a virtual actuator; thus, it might be queried or set by a command. In the example of the query of the weather forecast over the Internet, the gateway and the rest of
Page 67
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
the global network define a virtual sensor, which delivers data to the sensor network application. An actuator is a component that sets the state of the environment. We identify two types of actuators: 1. Simple actuators that are devices that map a data value into a physical quantity and may return an acknowledgment when the action is taken. Examples of actuators are devices that modify physical parameters, such as heaters and automatic window/door openers, as well as output devices, such as displays and speakers. 2. Virtual actuators that overall look like actuators in the sense that they receive values to set some parameters. Virtual actuators are defined by the list of parameters that can be set and by the primitives that are used for setting. Examples of virtual actuators are: • An actuator that provides an indirect way of controlling a certain environment condition by combining one or more physical actuators with processing (e.g., transformation, and decompression). • A controller whose parameters are set by other controllers. • A network getting commands to take actions through gateways. A detailed list of the relevant parameters of sensors and actuators is given in [52]. The most important feature, differentiating sensors and actuators from controllers, is that the former are purely reactive components; that is they will only read or set the state of the environment upon a request or command of a controller. Hence, only controllers can initiate events or sequence of events.
Columbus IST-2001-38314 WPBD
Page 68
4.2 A Standard for the Development of Implementation Independent Applications
4.2.2
The Query/Command Services: the Core of the SNSP
To ensure generality and portability, our proposal formalizes only the primitives that allow the Application to access the services of the SNSP, and does not define the architecture of the SNSP itself. In this section, we outline the functionality and the interface primitives for the two core services of the SNSP: Query and Command. Due to space limitations, we provide a detailed description only of the Query Service primitives. Details of the other services are given in [52]. Naming In AWSN applications, components communicate with each other because of specific features, often without knowing a priori which and how many components share those specified features. For example, a controller may want to send a message to all the sensors measuring temperature in a region, say in the kitchen. In this case, the group of temperature sensors located in the kitchen may be named and addressed for message delivery using the attributes ”temperature” and ”kitchen” rather than using the list of IDs of all the individual sensors having those attributes [53]. A name is an attribute specification and scope pair. An attribute specification is a tuple ((a1,s1), (a2,s2),... (an,sn), expr1, expr2,... exprl), where ai is an attribute; si is a selector that identifies a range of values in the domain of ai; exprk is a logical expression defined by attribute-selector pairs and logical operators. For example, a name can be defined by the pairs (temperature, = 30 C), (humidity, = 70 C) OR (humidity, = 70 commonly used for naming in sensor networks are the physical parameter being measured by sensors or modified by actuators (e.g. temperature, humidity). Attribute specifications are always understood within a scope. A scope is a tuple (O1, O2, ... On, R1, R2,... Rm), where Oi is an organization unit and Rj is a region.
Page 69
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
A region is a set of locations. We differentiate between two types of regions: • a zone is a set of locations identified by a common name; e.g. the kitchen or the SF Bay • a neighborhood represents a set of locations identified by their closeness to a reference point; e.g. all nodes within a radius of 10 m from a given location An organization is an entity that owns or operates a group of nodes. Organizations are essential to differentiate between nodes that operate in the same or overlapping regions, yet belong to different organizations (for instance, the police and the fire department). In general, names are and must not be unique. In addition, names may change during the evolution of the network because of the movement of nodes or the modification of some attributes. An essential assumption underlying the SNSP is that all the functions participating in the network (that is, controllers, sensors and actuators) always have a sense of their location within the environment. Query Service The Query Service (QS) allows a controller to obtain the state of a group of components. A query is a sequence of actions initiated by a controller (query initiator), which requests specific information from a group of sensors (query targets). If the requested information is not available, QS always returns a negative response within a maximum time interval, which has been set previously. Figure 4.2 visualizes the interactions of QS with the query initiator and the query target. In sensor network applications, query targets are typically sensors that provide controllers with the requested measures but in
Columbus IST-2001-38314 WPBD
Page 70
4.2 A Standard for the Development of Implementation Independent Applications
Figure 4.2: Query Service interactions
some applications the target may be a group of controllers (considered as virtual sensors) that are requested their current state. Queried parameters. In addition to the physical data being measured by a sensor, a controller may query other parameters related to the sensor, such as time (when the measure was taken), location (where the measure was taken), accuracy (how accurate was the measure), and security (if the measure comes from a trusted source). If no parameter is indicated in a query request, by default the response returns the data measured by the target sensors. The primitives of the Query Service are summarized in Table 1. The QS primitives use the following arguments. QueryID. Multiple queries, coming from the same or different controllers, can occur concurrently. QS uses a QueryID number to relate a query request with the corresponding responses. An arbitrary integer chosen by the QS (for example the timestamp indicating the time when the query request is sent) can be used as QueryID. The QueryID assigned to a query is always released as soon as the corresponding query terminates. Response Type. In a query, the controller specifies the frequency of the
Page 71
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
QSRequestWrite (Target, Parameter, QueryClass, ResponseType, Reliability) Initiates a query of the type indicated in QueryClass to obtain a Parameter from the components addressed by the name Target. It returns a QueryId as a descriptor of the query or Error. QSResponseRead (QueryId) Returns the value of the parameter, requested by the query identified by QueryId, if available. If it is not available, it returns a special value indicating the response has not arrived yet. QSClassSetup (Accuracy, Resolution, Timeliness, MaxLatency, Priority, Loc,TimeTag, Operation, Security, ...) Creates a QueryClass, configuring one up to all the parameters in the list. It returns the descriptor of the query class or ERROR QSClassUpdate (QueryClass,
Accuracy,
Resolution,
Timeliness,
MaxLatency, Priority, Loc,TimeTag, Operation, Security, ...) Updates one up to all the set of parameters of a QueryClass previously defined. QSStopQuery (QueryID) is used by a query initiator to stop a query and release the QueryID for use in future queries. It returns OK or Error. Table 4.1: Query Service primitives
Columbus IST-2001-38314 WPBD
Page 72
4.2 A Standard for the Development of Implementation Independent Applications
responses it expects from the sensors. Three types of response patterns are especially relevant: • one-time response • periodic responses with interval period p • notification of events whenever an event specified by an event condition occurs Reliability. A query is reliable if the query initiator is guaranteed to receive at least one response, which has not been corrupted. In all other cases, the query is said to be unreliable. The default case is the unreliable query. If a reliable query is requested this has to be explicitly specified. The support for reliable queries is provided, within the query service, by means of specific reliability assuring mechanisms. Query Class. A given query can be subject by a wide range of constraints such as accuracy, timeliness, etc. One option is to repeat all these constraints with every QueryRequest. This would make the query messages traveling through the network quite heavy, which does not fit well with the energy-efficiency and light- weight requirements typically imposed on sensor networks. The Query Class allows for a one-time definition of the context of a query by defining and constraining the response scope. The following parameters can be set: • Accuracy and resolution of the sensor measures. • Timeliness, MaxLatency and Priority define response time constraints on the Query • Loc,TimTags indicate if the query response should include time and location tags. • Operations such as max, min, average. They indicate the type of operation to be performed on multiple measures from the same source.
Page 73
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
• Security. It indicates if the data must be secure or not. • Other constraints ... All the query instances belonging to a certain class must follow the parameters of that class. QS operation. Figure 4.3 plots a sequence of primitive function calls associated with a query. The QS execution follows the client-server model. First, the query class parameters are initialized using QSClassSetup. Then, the controller calls the QSRequestWrite function to initiate individual queries. QS returns the query descriptor (QueryID) to the controller which is blocked waiting for an immediate answer on whether the query can be initiated. If the answer is negative, an error message is returned. If the query is successfully initiated, QS begins the procedure of getting the parameter requested by the application. Observe that the service does not specify how the data is obtained. For instance, instead of getting a new sensor measure, the QS may reuse local information previously gathered if the queried parameter is still available from a previous query and satisfies the timeliness requirement. In addition, the QS may perform additional functions such as aggregation to process the data coming from multiple sensors. To access the values of the queried parameter, the controller calls the QSResponseRead primitive specifying the QueryID parameter. A query with a one-time response or an event notification terminates either when the response arrives or when a timeout of duration max time set by the query initiator expires. The timeout prevents a query from staying active for an unnecessarily long time, especially when it is not known a priori how many responses will be received. It also allows the corresponding QueryID to be released. In the case of a periodic- response query, the query can be terminated at any time by the application simply calling the QSStopQuery primitive.
Columbus IST-2001-38314 WPBD
Page 74
4.2 A Standard for the Development of Implementation Independent Applications
Figure 4.3: Query Service execution. Controller/QS interactions are defined by the AI, while the QS/Sensor interface is implementation dependent and might follow for example the IEEE 1451.2 standard
Page 75
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
QSRequestRead (parameter) provides a virtual sensor with the name of the parameter being requested QSResponseWrite (parameter, value) provides the value for a requested parameter Table 4.2: Primitives used for the interaction with Virtual Sensors Additional primitives used by Virtual Sensors. Virtual Sensors necessitate the introduction of the following primitives, reading the parameter being queried, and writing the corresponding value, respectively acting as counterparts for the corresponding functions in the controllers. As a special case, controllers acting as virtual sensors use them to interact with other controllers that have queried their parameters. These primitives substitute the implementation dependent QS/Sensor interface used for simple sensors. Command Service The Command Service (CS) allows a controller to set the state of a group of components. A command is a sequence of actions initiated by a controller (command initiator), which demands a group of components (command targets) to take an action. The Command Service operates completely symmetrical to the Query Service defined above-its primitives are hence omitted for the sake of brevity. One major difference should be pointed out - while requests are self-confirming (that is, a set of values is returned), commands are not. Often, there is a need to know if a command has reached its targets. Hence, we differentiate between commands of the type confirmed (where actuators return an acknowledgment to the controller after the action is taken) or unconfirmed (if they do not send any acknowledgment).
Columbus IST-2001-38314 WPBD
Page 76
4.2 A Standard for the Development of Implementation Independent Applications
4.2.3
Auxiliary Services
Concept Repository Service The Concept Repository Service (CRS) maintains a repository containing the lists of the capabilities of the network and the concepts that are supported. The CRS plays a key role in the network operation because it allows distributed components to refer to common notions of concepts such as names, attributes and regions. Moreover, it maintains agreement on these concepts in the presence of changes occurring dynamically during the network operation (e.g. new nodes join the network, or existing nodes move across region boundaries). In line with the philosophy of this paper, we do not prescribe how the CRS is implemented. For instance, the CRS may be centralized or distributed over the network. In both cases the correct operation of the system requires that the repository be updated in a timely manner when parameters change. For example, a node that moves from the kitchen to the living-room must update the region in which it is located and therefore must check which region includes its new coordinates. While the Location Service (Section 4.3) gives a node its new spatial coordinates, the CRS provides the node with the association of these coordinates with the ”living-room” region. In addition to supporting the operation of a single network, CRS supports the interoperation of multiple networks (discussed in [52]) since it provides a complete and unambiguous definition of the capabilities of each network. CRS holds the definition of the following concepts: 1. Attributes, used to define names. Examples of attributes, common especially in environment monitoring applications, are temperature, light, and sound. Attributes can be added to the repository either by the application or automatically (”plug-and play”) by the CRS, when the platform is augmented with sensors (or actuators) that read (or
Page 77
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
write) a new attribute. 2. Regions, used to define the scope of a name. The name of a zone is added to the repository together with the zone boundaries, expressed in terms of the spatial coordinates. During the network operation, a component that knows its spatial location can get through the CRS also the name of all the zones that include its location. 3. Organizations, used to define the scope of a name. Organizations indicate who owns or operates certain groups of nodes (e.g. the police, the fire department). The capability of distinguishing nodes by organization is necessary when there are nodes performing the same function (e.g. sensor nodes of the same type) in the same region, but are deployed and used to achieve a different task or belong to a different owner. 4. Selectors, logic operators and quantifiers, used to define names and targets of queries and commands. The following types are the most commonly used: • selectors: ¿ n, ¡ n, even, odd, =. • logic operators: OR, AND, NOT • quantifiers: all, at least k, any The CRS primitives allow to Add or Delete an attribute (or a region or an organization), Get the list of all the defined attributes (regions, organizations) and Check if a given attribute (region, organization) is currently present in the repository. Time Synchronization Service The Time Synchronization Service (TS) allows two or more system components to share a common notion of time and agree on the ordering of the events that occur during the operation of the system.
Columbus IST-2001-38314 WPBD
Page 78
4.2 A Standard for the Development of Implementation Independent Applications
Typical application scenarios that require time synchronization are ”heat room at 6 pm” or ”send me the temperature within 5 seconds”. The TSS is used to measure time and check the relative ordering among the events in the system. If the events to be compared belong to the same component (e.g. ”retransmit message if acknowledgment is not received within 10 seconds”) only local resources such as clock and timers are used. If they belong to different components, TSS uses a distributed synchronization algorithm to ensure that their clocks are aligned in frequency and time value. A component can be in synchronized or not-synchronized state. If it is in not- synchronized state, time is measured by the local clock and is called individual time. If it is in synchronized state, the time value is agreed with one or more other components, which share a common reference. Synchronizing multiple components may require a time interval, called synchronization time, and can be achieved up to a certain specified accuracy. The synchronization scope of a component is defined by the set of components with which it is synchronized. TSS primitives allow to setup the resolution and accuracy of synchronization (TSSSetup), activate or deactivate the synchronization with components specified in a given scope (TSSActivateSynchronization), get the time (TSSGetTime), and set a timer to expire after a given number of time units (TSSSetTimer).
Location Service (LS) The Location Service (LS) collects and provides information on the spatial position of the components of the network. The operation of sensor networks commonly uses location as a key parameter at several levels of abstraction. At the application level location is used for example to define the scope of names in queries (e.g. ”send me the temperature measures from the kitchen”). Depending on the use, location
Page 79
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
information can be expressed as a point in space or by a region where the node is located. A point location, or simply location, is defined by a reference system and a tuple of values identifying the position of the point within the reference system. LS supports the definition of location in a Cartesian Reference System, where location is expressed as a triple (x,y,z), with x, y and z representing respectively the distance from the origin along the axis x, y, and z. Regions can be easily expressed within this framework. A zone can have the form of a block, a sphere, a cylinder, or a more complex shape. A block is represented in terms of the coordinates of four vertices, while a sphere is represented by the center and the length of its radius. Neighborhood is a region defined by the proximity to a reference point. Proximity is expressed either in terms of Euclidean distance (spherical region) or by the number of routing hops. LS primitives allow to setup the resolution, accuracy and reference system (LSSetup), get the location of a component (LSGetLocation), and get the list of the regions including a specified location (LSGetRegions). It is often useful for a controller to know what type and how many nodes are located in a given region. Also, it maybe useful to know if these nodes are static (that is, have not moved for a long time), or are mobile. It turns out that this information can be readily obtained using the primitives defined in the Query Service querying for parameters ”location” and ”mobility”. To find the number of temperature sensors in the kitchen region, it suffices to launch a query for parameter ”location” with name ”(temperature, kitchen)” and to determine the cardinality of the returned list.
4.2.4
A Bridge to the AWSN Implementation
The SNSP and the AI, as described, are purely functional entities, which are totally disconnected from the eventual implementation. The only nod to
Columbus IST-2001-38314 WPBD
Page 80
4.2 A Standard for the Development of Implementation Independent Applications
performance metrics is that queries and commands can identify constraints on timeliness, accuracy, etc. However, one of the differentiating features of AWSNs is that implementation issues such as the trade-off between latency and energy- efficiency play a crucial role. Conserving independence from implementation, while being sensitive and transparent to implementation costs, is an essential part of this proposal. To accomplish these goals, a second platform is defined. The Sensor Network Implementation Platform (SNIP) is a network of interconnected physical nodes that implement the logical functions of the Application and the SNSP described earlier. Choosing the architecture of the SNIP and the mapping of the functional specification of the system properly is a critical step in sensor network design. The frequency of the processor, the amount of memory, the bandwidth of the communication link, and other similar parameters of the SNIP ultimately determine the quality and the cost of the services that the network offers. Figure 4.4 visualizes the concept of mapping the Application and the SNSP functions onto the SNIP nodes Ni. The shaded boxes and the dotted arrows associate groups of logical components with physical nodes. An instantiated node binds a set of logical Application or SNSP functions to a physical node. Physical parameters such as cost, energy efficiency, and latency can only be defined and validated after mapping. The operation of the Application or the SNSP may depend upon the value of a physical parameter of the SNIP (for instance, amount of energy level, quality of the channel, etc). To make this information available in a transparent fashion, an additional service called the Resource Management Service (RMS) is provided, which allows an application or other services of the SNSP to get or set the state of the physical elements of the SNIP. Typically, the RMS can access physical parameters such as the energy
Page 81
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
Figure 4.4: Mapping Application and SNSP onto a SNIP level of a node, the power management state, the quality of the radio channel, the energy cost of certain operations and their execution time, the transmission power of the radio. The RMS can be accessed using the same primitives offered by the QS and the CS. The main difference is that the parameters being set or queried do not belong to the environment but to the physical nodes of the network.
4.2.5
Summary
A service-oriented platform for the implementation of AWSN applications was presented. We believe that by defining an application interface at the service layer, it should be possible to develop and deploy sensor network applications while being agnostic about the actual network implementation yet still meeting the application requirements in terms of timeliness, lifetime, etc. Some of the concepts introduced in this paper have broader applicabil-
Columbus IST-2001-38314 WPBD
Page 82
4.3 Design of AWSN Using the PBD Paradigm
ity than AWSNs. For instance, a concept such as the CRS would also be useful in the operation of ad-hoc multimedia networks. In fact, the development of a service- based application interface for this emerging class of applications in a style similar to the one presented here seems like a logical next step - the potential success of ambient intelligence hinges on the simple and flexible deployment of both media and sensor networks and the interoperability between the two.
4.3
Design of AWSN Using the PBD Paradigm
A specification can be loosely defined as a description of a system. It may be informal and consist of just a few graphical sketches or sentences in natural language, or be formally described using a language with formal semantics. The design of a system consists of a sequence of steps, in which new details are gradually introduced until the physical implementation. Each step identifies a specification at a different level of abstraction. At the most abstract levels, a specification defines the functionality of the system as a whole, at more refined levels, it usually consists of a network of distinct components interacting and cooperating to realize a required collective behavior. The behavior of a system is defined by the sequences of actions that it takes as a response to input stimuli from its environment. Actions [54] [4] are the elementary units of behavior that make the system evolve from one state to another. Actions can be of several types: computation (perform arithmetic operations), control (select the next action to be taken), read/write (read or modify variables). Embedded systems specifications, especially in networking and multimedia applications, are heterogeneous and include a mix of different types of actions. Two actions whose order of execution is not specified are said to be concurrent, as they may occur in any order or at the same time. They are said to be in conflict, if either one is executed as a result of a control decision. They are causally ordered, if one
Page 83
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
is always executed before the other. Distributed system specifications usually consist of sequential objects that run concurrently and communicate through other objects called channels storing the messages they exchange. A specification is usually associated with a set of constraints that are expressions on quantities that are not defined in the present specification yet, but will be defined after further implementation steps. In other words, constraints define properties that must be satisfied by valid implementations of a given specification. For example, bounds on the communication delay are usually given at the beginning of the design process, but quantities such as time and power are defined only after an implementation architecture is selected (e.g. choosing the processor that runs the software tasks defines the reaction time of an embedded system implementation). In a distributed system specification, the network supporting the communication among components is one of the major factors of complexity. The initial network specification is defined by the behavior of the interacting components and is associated with cost and performance requirements. As the design proceeds, the network specification is successively refined: the structure is described in terms of the topology (nodes and links), the behavior in terms of the protocols that rule the exchange of messages among components. Protocol specifications include several types of actions, that are either in sequence (“send an acknowledgment after receiving the packet”), or in conflict (“forward packet to upper layer if correct otherwise discard it“), or concurrent (“write to multiple channels”). Constraints on protocol implementations usually concern QoS parameters such as error rate, throughput, maximum delay, duration of a service etc. [55] [56] The types of actions in a protocol specification and the type of constraints drive the choice of the physical resources that define the physical implementation. Protocols can be fully implemented in HW, in SW, or as a mix of the two. HW is the preferred choice for protocols with tight power and real-time requirements. SW implementations are chosen when mostly flex-
Columbus IST-2001-38314 WPBD
Page 84
4.3 Design of AWSN Using the PBD Paradigm
ibility matters and timing and power issues are not so critical. Therefore, protocols are usually implemented partially as software tasks running on a processor and partially as Application Specific Integrated Circuits (ASICs) and Field Programmable Gate Arrays (FPGAs). Communication networks are commonly designed decomposing the problem into a stack of layers following the OSI reference model. Each protocol layer with the underlying channels defines a platform that provides communication services to the upper layers and, at the top of the stack, to the application-level components. There is an ongoing debate about the use of the OSI protocol stack since, as we shall see in the next section, its layering structure is standard and application-independent, therefore, rather inefficient to use in those applications where optimization is of paramount importance such as wireless sensor networks. Our approach presented here is to leverage the idea of layering the protocol stack in the design of wireless sensor network as in the OSI model but not to fix a priori the layers themselves. By allowing the freedom of choice in the layer structure, we aim to optimize along criteria such as power consumption, reliability and response time since the applications of wireless sensor networks depend critically on these quantities. As a result, the protocol stack architecture includes only the layers that are relevant for the target application and the protocol functions, rather than being assigned a priori to specific layers, are introduced in the position where the services they offer are required. To implement an AWSN networks, the functionality is mapped onto a Network Platform (NP) that consists of a set of processing and storage elements (nodes) and physical media (channels) carrying all the messages exchanged by nodes [2]. Nodes and channels are the architecture resources in the NP library and can be identified to a first extent by some parameters like processing power and storage size for nodes, and bandwidth, delay and error rate and for channels. Usually, choosing a Network Platform requires selecting from its library
Page 85
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
an appropriate set of resources and a network topology: for each parameter a broad range of options is usually available. Therefore, the design space to be explored is very wide. Moreover, choosing an NP is especially challenging for distributed wireless networks, because of the inherent lossy nature of the physical channels that connect the nodes. In these cases, when reliable communication is required, like in our system target, it is necessary to introduce additional resources (that is, reliable acknowledgement protocols) to overcome the effects of noise and interference. However, introducing reliable and complex protocols requires adding more processing power and more memory capabilities in the nodes. As a result, the protocol constraints often dominate the implementation cost function and the design effort. Therefore, in selecting an NP it is essential to balance the cost of all different components and to trade between the use of complex protocols and the adoption of more reliable physical or logical wired/wireless channels. The section is organized as follows: we begin by reviewing the OSI standard and pointing out its strengths and weaknesses. Then we propose the definition of Network Platform including quality of service parameters and give some examples.
4.3.1
Communication Networks: OSI Reference Model
A common practice to simplify the design of general purpose communication networks consists in dividing the problem into different layers of abstraction, according to the Open Systems Interconnection (OSI) Reference Model (RM) that was standardized by the International Standard Organization (ISO) in 1983 and, since then, widely used as a reference to classify and structure communication protocols [17]. The OSI-RM groups the protocol functions into the following seven layers [18]: 1. Application Layer: defines the type of communication between ap-
Columbus IST-2001-38314 WPBD
Page 86
4.3 Design of AWSN Using the PBD Paradigm
Figure 4.5: OSI-RM layering structure [3] plication processes and links them to the lower layers of the stack. Examples: HTTP, SMTP, FTP. 2. Presentation Layer: defines the format of the data being transferred, by performing transformations such as encryption, compression, conversion between coding formats. 3. Session Layer: coordinates the establishment and the maintenance of connections among application processes. It inserts synchronization points in the data stream to allow resynchronization in case of errors. 4. Transport Layer: provides reliable communication among end users through functions such as segmentation and reassembly, flow and error control. Examples: TCP, UDP. 5. Network Layer: establishes connections across sub-networks and intermediate nodes by choosing a route from source to destination and forwarding packets along this route. 6. Datalink Layer: provides reliable communication over a link by packaging bits into frames or packets and ensuring their correct communication. It includes a Logical Link sub-layer, with error detection or correction functions such as CRC, FEC, ARQ, and a Medium Access Control sub-layer, that defines a policy for arbitrating the access to a shared medium. Examples: HDLC, SDLC, X.25. 7. Physical Layer: takes care of the transmission of a bit stream over a physical channel by defining parameters such as the electric level, and including functions such as modulation and encoding. The OSI-RM is based on the concepts of protocol and service, as illustrated in Figure 4.5. A service is a set of operations (primitives) that a layer offers
Page 87
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
to upper layers. A protocol layer defines an implementation of the service primitives and, similar to API, their details are hidden to upper layers. Let us consider Layer N in Figure 4.5: this layer provides services that Layer N+1 uses to communicate with its peer in a remote host. Layer N+1 invokes the service primitives available at the interface with Layer N (interfaces are called Service Access Points or SAPs) and communicates over the virtual channel made available by Layer N and the lower layers. Every message is passed through all lower protocol layers in the local host and then transmitted to the remote host over the physical medium. At each layer, a frame including the payload data and a header with control information is created and passed to the lower layer. When the frame arrives at the receiver end, each layer takes off and interprets the header introduced by the corresponding layer at the sender host and passes the rest of the frame to the upper layer. The use of the OSI-RM has several advantages. First of all, identifying layers from the beginning of the design process allows to decompose the problem into a number of independent and easier to handle sub-problems delimited by well-defined interfaces. This approach implies high modularity, because the interactions between adjacent layers are limited to the service primitives in the SAPs. Therefore, a layer can be easily replaced with another one only if it has consistent interfaces and provides comparable services, without the need of modifying other layers of the stack. Applying such a modular approach also allows to partition the workload among different teams, whose work can proceed in parallel once they agree on the common interfaces. However, there are also several drawbacks concerned with the use of the OSI-RM [15]. First of all, the layers are against any form of cross-layer optimization and therefore limit the performances theoretically achievable. The main problem is that often distinct protocol layers manipulate the same data, and it is inefficient to repeat the load and the store of these data from
Columbus IST-2001-38314 WPBD
Page 88
4.3 Design of AWSN Using the PBD Paradigm
memory for each layer. It is rather convenient to read the data from memory once and perform as many manipulations as possible while holding the data in cache or registers [19]. Another issue is the semantic isolation of the protocol layers: that is, each layer knows only the meaning of the data defined at that level. This means that a certain layer is not aware of the meaning of the contents exchanged by the upper protocol layers or arriving from the lower ones. For example, let us consider the well known issue of the poor performances of the TCP protocol [20] over a wireless medium. The TCP protocol provides reliable communication by using a window scheme that regulates the transmission rate based on a network congestion control algorithm. The protocol is based on the assumption that the underlying medium is reliable and that losses due to noise are negligible if compared to those due to buffer congestion. This assumption is not valid at all for a wireless medium. Hence, when TCP runs over a wireless channel, packet losses due to the low Signal to Noise (plus Interference) Ratio are misinterpreted by the protocol, which reduces the transmission rate to avoid network congestion. As a result, the throughput of TCP over a wireless link is rather low. In conclusion, the OSI-RM is commonly used as a reference, especially because the concepts of layering and service allow to simplify complexity of the network design problem. However, applications that require protocol functions not included in the OSI-RM (e.g. positioning in the wireless sensor networks) and the increasing demand for high performance protocols have further emphasized the limitations of the OSI approach and the need of highly optimized protocol stacks [3].
4.3.2
Network Platforms
A Network Platform (NP) is a library of resources that can be selected and composed together to form Network Platform Instances (NPIs) and to support the communication among a group of interacting objects. An NP li-
Page 89
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
brary includes resources of different type. One distinction is between logical resources (e.g. protocols, virtual channels...) that are defined only in terms of their functionality and physical resources (e.g. physical links). An orthogonal distinction is between resources that perform or implement computation functions and communication resources that provide logical or physical connectivity. The structure of an NPI is defined abstracting computation resources as nodes and communication resources as links. Ports interface nodes with links or with the environment of the NPI. Hence, the structure of a node or a link is defined by its input and output ports. The structure of an NPI is defined by a set of nodes and the set of links connecting them. The behavior of an NPI is formalized using the Tagged Signal Model introduced by Lee and Sangiovanni-Vincentelli. Before diving into the precise definition of Network and Network API Platforms, we summarize the model to make the report self consistent.
Preliminaries: the Lee-Sangiovanni-Vincentelli Tagged Signal Model The Tagged Signal Model [21] is a denotational [22] framework proposed by Lee and Sangiovanni-Vincentelli to define properties of different models of computation. The denotation of a system component modeled as a process is given as a relation on the signals that define its interaction with concurrent processes. Concurrent processes have sets of behaviors, each defined as a tuple of input and output signals. In the TSM the event is the key modeling element. Given a set of values V and a set of tags T , an event e is defined as a member of T × V . Tags are used to model precedence relationships, values represent tha data associated with an event. A signal s is a set of events, i.e. a subset of T × V . Functional signals are (partial) functions from T to V . The set of all signals S = ℘(T × V ) (powerset of T × V ), while S n is the set of all tuples of n signals. A process P is a subset of S n where n is the number of input or
Columbus IST-2001-38314 WPBD
Page 90
4.3 Design of AWSN Using the PBD Paradigm
Figure 4.6: Process Composition in TSM
output signals. A signal s s.t. s ∈ P is a behavior of P . If n > 1 a process can be seen as a relation between the n signals. The composition of multiple processes is defined as a process Q whose behaviors are in the intersection of the behaviors of the component proT 0 cesses. Hence, Q = Pi , where Pi0 is derived from Pi augmenting the signal tuples so that they are defined in terms of the same set of signal S n (Pi0 ⊆ S n ). Connections are modeled as processes where two or more signals must be identical. Figure 4.6 shows the interconection of two processes P1 and P2 through connections C27 (signals s2 and s7 ) and C45 (s4 and s5 ). The projection πI (s) of a signal s = (s1 , s2 , ...sn ) ∈ S n onto S m is πI (s) = (si1 , si2 , ...sin ), where I = (i1 , i2 , ...im ) is an ordered set of indices in the range [1,n], that defines the signals that are in the projection and which order they appear. Projection simplifies the composition of processes by removing redundant signals. The definition of processes as relations among signals is general and does not distinguish between input and output signals. To introduce this distinction, [21] defines an input to a process P as a constraint A ⊆ S n imposed to P so that A ∪ P is the set of acceptable behaviors. B denotes the set of behaviors of a process for a set of possible inputs. Consider a process
Page 91
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network P ⊆ S n with m input signals. Then, for each A ∈ B, A = {s : πI (s) = s0 } for some s0 ∈ S m . To define a process in terms of a mapping of input signals into output signals, consider an index set I for m input signals and an index set O for n output signals. A process P is functional with respect to (I,O) if for every s ∈ P and s0 ∈ P , where πI (s) = πI (s0 ), it follows that πO (s) = πO (s0 ). For such process there is a single-valued mapping F : S m → S n such that ∀s ∈ P , πO (s) = F (πI (s). Tags are used to define ordering among events. An ordering relation ≤ on a set T is a relation on T such that, for all t1 , t2 and t3 : • t1 ≤ t1 (reflexive), • t1 ≤ t2 and t2 ≤ t3 imply t1 ≤ t3 (transitive), • t1 ≤ t2 and t2 ≤ t1 imply t1 = t2 (antisymmetric). A set with an ordering relation ≤ is called partially ordered set or poset [23]. The ordering of tags induces an ordering of the corresponding events. In untimed models events are partially ordered, while in timed models such as Discrete Event the set of tags T is totally ordered. Network Platform Defined NPI components are modeled as processes. The event is the communication primitive. Events model the instances of the send and receive actions of the processes. An event is associated with a message which has a type and a value and with tags that specify attributes of the corresponding action instance (e.g. when it occurs). A signal is a totally ordered sequence of events observed at one port 1 . The set of behaviors of an NPI is defined by the intersection of the behaviors of its individual component processes. 1
We consider only discrete signals, because analog signals, under the conditions defined
by the Nyquist Sampling Theorem [24], can be described in terms of the equivalent discrete signals.
Columbus IST-2001-38314 WPBD
Page 92
4.3 Design of AWSN Using the PBD Paradigm
A Network Platform Instance is defined as a tuple N P I = (L, N, P, S), where • L = {L1 , L2 , ...LN l } is a set of directed links, • N = {N1 , N2 , ....NN n } is a set of nodes, • P = {P1 , P2 , ...PN p } is a set of ports. A port Pi is a triple (Ni , Li , d), where Ni ∈ N is a node, Li ∈ L ∪ Env is a link or the NPI environment and d = in if it is an input port, d = out if it is an output port. The ports that interface the NPI with the environment define the sets P in = {(Ni , Env, in)} ⊆ P, P out = {(Ni , Env, out)} ⊆ P • S =
T
N n+N l
Ri is the set of behaviors, where Ri indicates the set of
behaviors of a resource that can be a link in L or a node in N
4.3.3
Network Platform API
An NPI is uniquely identified by its components and by the intersection of their individual behaviors. A more convenient description of an NPI is one where the details of its internal components are abstracted away and only the behaviors observed at the P in and P out ports are considered. Hence, one abstraction of the NPI behavior is simply defined by projecting the Q behaviors s ∈ S over P in and P out : S 0 = (P in ∪P out ) S. Another abstraction can be defined by taking into consideration the semantics of an NPI. An NPI is an entity whose purpose is to support the transfer of messages among its users connected through the ports P in ∪ P out . Therefore, events observed at the input and output ports of an NPI are highly correlated: an event observed at an output port frequently carries the same message as another event observed at an input port. Multiple events at the same port may carry messages related to the same transaction and therefore to the same group of users. This observation allows to identify within the NPI behaviors subsets of correlated events that correspond
Page 93
Columbus IST-2001-38314 WPBD
Platform-based Design for Wireless Ad-hoc Sensors-Network
to sequences of exchanges of messages between the components communicating over the NPI (NPI users). The basic services provided by an NPI are called Communication Services (CS). A CS consists of a sequence of message exchanges through the NPI from its input to its output ports. A CS can be accessed by NPI users through the invocation of send and receive primitives whose instances are modeled as events. An NPI Application Programming Interface (API) consists of the set of methods that are invoked by the NPI users to access the CS. For the definition of an NPI API it is essential to specify not only the service primitives but also the type of CS they provide access to (e.g. reliable send, out-of-order delivery etc.). in
A Communication Service (CS) is a tuple (P , P P
in
⊆ P in is a non-empty set of input ports, P
out
out
, M, E, h, g,