Keywords-Depth filtering, Kinect, video decomposition, total variation (TV). I. INTRODUCTION. As image is formed from the projection of the 3D world onto a 2D ...
2015 Third International Conference on Image Information Processing
Depth Filtering Using Total Variation Based Video Decomposition Saumik Bhattacharya, K. S. Venkatesh, Sumana Gupta Indian Institute of Technology Kanpur, India
{ saumik,
venkats, sumana @iitk.ac.in
}
the depth which make the distortion both time varying and depth varying. Due to this inherent problem of Kinect, several authors have proposed different approaches to filter the depth data to get high accuracy depth map where the color image taken from the RGB camera of the Kinect has exact point to point correspondence with the depth image. The most common way to suppress the distortion is to use traditional filtering techniques like bilateral filter or Kalman filter [13], [14]. Though these filters reduce the distortion, the edges of the depth map become blurred. Lai et al. proposed a method to filter the depth map using the corresponding RGB information of the scene [14] but the algorithm largely depends on the camera calibration and performs poorly for larger depth. In this paper, we use a depth video and its corresponding color video to measure a high accuracy depth map of the scene. The distortion is removed by decomposing the depth video into two parts- video with visually similar frames and residual video with distortion and motion. Further the residual depth video is filtered using the motion information present in the color video. The method can generate high accuracy depth map for static scene as well as dynamic scene. Our Contributions: • Unlike the existing filtering methods, which exploit only the spatial information, the proposed algorithm uses spatio-temporal information to estimate the high accuracy depth map. • The proposed algorithm can estimate accurate depth map in static scene as well as in dynamic scene. • The proposed algorithm incorporates the information present in the color image, thus gives point to point correspondence between the RGB image and its depth image. Rest of the paper is divided into following sections section 2 contains the proposed algorithm for depth filtering, experi-mental results in different conditions are presented in section 3 and section 4 contains the discussion and final comments about the proposed algorithm.
Abstract-In vision based applications, depth plays a crucial
role from different aspects. From 3D rendering to automation, precision in depth measurement is important for acceptable performances. Though several techniques have been proposed to capture depth map of a scene, the estimation is either erroneous or much expensive for regular usage. Thus, the demand for high accuracy depth measurement is prominent in the field of robotics and computer vision. In this paper, we propose a method to estimate high accuracy depth map from a raw depth map for both static and dynamic scenes. This depth filtering is done by exploiting the spatio. temporal information present in a depth video and by taking the color information of the scene into account.
Keywords-Depth filtering, Kinect, video decomposition, total variation (TV).
I.
INTRODUCTION
As image is formed from the projection of the 3D world onto a 2D sensor, depth of the scene is inherently missing in any image taken from normal imaging devices. Thus several attempts have been made to estimate the depth of a scene by using external hardware or multiview [1]-[5]. In the multi view based depth estimation, depth from stereo is particularly popular due to its simpler mechanism [6]-[8]. Though, it gives a coarse depth estimation of a scene from two laterally shifted images, it goes drastically wrong for the regions where the texture information is either less or completely absent. Another method, known as 'depth from defocus', tries to estimate the blur kernel from a single image at a particular pixel location and assuming the focal point close to the camera center, estimates the relative depth of the scene as blur kernel radius is proportional to depth [9], [10]. Unfortunately, this method also fails for regions with low texture information. To cope with the problems, external hardware is used to project coded light pattern on a scene and depth is estimated from the deformation of shape of the light pattern. This method is known as structured light method which is used extensively to calculate depth in different purposes [11], [12]. Nowadays, Kinect is used to measure the depth of a scene by projecting an IR structured light pattern. Kinect is particularly popular as it is cheap and can measure the depth in real time. Instead of these prominent advantages, it is difficult to use Kinect for sophisticated applications like telesurgery, 3D rendering, etc. as the depth map, produced by Kinect, heavily suffers from distortion. The distortion is dependent on the IR pattern and the region growing algorithm that are used to measure
II.
PROPOSED ApPROACH
The proposed depth filtering process has two steps- decom position of the RGB color video as well as the depth video separately to two videos- one with visually similar sequence of frames and another with the feature information, and filtering of the featured video of the depth data using the feature video of the RGB data.
•
978·l·5090·0l 48·4/l5/$31.00© 2015 IEEE
23
IEEE
�computer society
2015 Third International Conference on Image Information Processing
1
(a)
(c)
(b )
Here we substitute h norm with max r where -1 :S r :S to avoid the non-differentiability of II norm Eq. 3 can be solved iteratively using the majorization minimization algorithm [15], [16], and we can estimate Op as A Op = Op - - MTr ( 5)
(d)
2
Assuming a shrinkage function, H(" T), we can estimate r as (e)
(g)
(f)
r(i+1) = H(r(i) � M �i+ ) , �) +
(h)
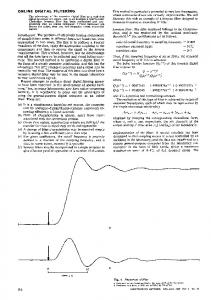
(a) Intensity map of an RGB frame; (b) estimated visually similar frame, i.e. the background; (c) corresponding feature frame which reflects the motion present in the video; (d) estimated binary mask; (e) raw depth map of the corresponding dynamic video; (f) estimated depth map of the background; (g) feature part of the corresponding depth map with distortions (h) rectified part of the feature depth map.
- {TSign(r)
.. . ,
A(p, K)]T
mi
n�ze
subject to
[
I
{ Op - Op A
�
ll:
A IIMOpI11}
0
A.
( 1)
To solve eq. �(Op)
2,
o
( 2)
D
D
DD D
D
(�
if F� � Th otherwIse
Fib(PJ= {I, Xi(PJ
(7)
where denotes the intensity value at the pixel location p of the ith frame of video and Th is a constant chosen heuristically. Ideally, in the absence of sensor noise, Th should be equal to zero, but in actual cases, it should have a small positive value. The binarized video Fb shows the regions where motion actually happens during the capture. We construct the final depth video f as
-1 +
+
-l�r�l f!p
D
0,
ll: A IIMOpI11} I min { I Op 0.11P 22 A max rTMOp} � max minj(Op,r) �
otherwise
D
we define a cost term �(Op) as I1J n { Op - Op
Depth filtering
D
�1 -11 o1 o
1,1 :S T
Let us assume that is a depth video of a corresponding color video F where each frame of contains the depth map of the scene present in F. Using the total variation based decomposition we decompose the videos into two parts each. The depth video is decomposed into Land s where Lcontains the visually similar frames and s contains the moving features. Similarly, the color video F is decomposed into F Land Fs using the same optimization algorithm. It is important to note that the video F L will contain the background image and Lwill contain the depth map of the background, whereas Fs will contain the motion information of the video and s will have the time varying distortions and the depth of the moving objects. To filter the depth video, we first binarize the feature color video Fs as
where A is the regularization parameter and M is the total variation matrix defined as
M=
(6)
Finally form the input video A, we construct two videos B and C such that B (p, i) = O� and C (p, i) = O� - O� , where Y� selects the ith element of vector Yp. The frames of the video B are visually similar whereas C contains rest of the features of the input video.
where A(p, k) denotes the intensity value at position p of kth frame. From the data Op, we try to estimate a vector Op such that the estimated vector is temporally less varying than Op by solving the following optimization equation +
,
H(" T ) -
For ease of discussion we will first discuss the total variation (TV ) based video decomposition model in general and then we will use the decomposition model to refine the depth map of a scene. Let a video A has K frames and dimension of each frame is r x q. For the given video, we first define a vector Op for pixel location p as
1), A(p, 2),
l
where i is the no. of iteration, a is the iteration step size and can be calculated from the relation a � maxeig(MMT), using the intialization rO = 0 and H(" T) is defined as
Fig. 1.
Op= [A(p,
O
X
D
Ds(PJ, Di (pn'l = {DL(PJ, D Ds D f
-l�r�l
( 3)
J}
if F� ( > otherwise
PJ
0
( 8)
For static scenes, contains only the time varying dis tortions and Lcontains the depth information of the scene. As no motion is there for a static scene, all the elements of Fb becomes zero and f will contain only Lwhich is the
where ( 4)
24
D
2015 Third International Conference on Image Information Processing contains the rectified depth information, while the feature part will contain the time varying distortions. In fig. 2 we show the outputs of the proposed algorithm for static scene as well as for dynamic scene. It can be easily visualized that the raw depth map has significantly low point to point correspondence as in several places the depth value is not correct due to the presence of distortion., whereas in the modified depth map, the depth values correspond to the RGB pixels exactly. As there is no ground truth available for these scenes, we use mean opinion scores (MOS) of twenty viewers to quantify the quality of the modified depth maps comparing them with the raw depth maps. Each user is asked to rate the raw depth map and the modified depth map between 0- 10, where 0 reflects very poor point to point correspondence and 10 reflects exact point to point correspondence, and then the mean of all the scores are calculated to quantify the raw video and the modified video respectively. In fig. 3, we show the MOS for the dataset that we use in fig. 2.
actual distortion free depth map of the scene. For dynamic videos, Fb will contain the pixel locations where motions occur. Thus, the depth of only those points are chosen and superimposed on the background depth to get the depth video of a dynamic scene.
(a)
(b )
(c)
(d )
(e)
(f)
(g )
(h)
(i) _Raw • M od ified
(k )
(j)
(1) 0
(m)
(n)
Fig. 3.
(0)
in fig. 2
Plot of the mean score opinion for the three dataset shown
IV. (p )
(q )
Estimation of high accuracy depth is much desired, yet a difficult process. Kinect provides a convenient solution to measure the depth of a scene using IR structured light. But it suffers from various distortions which makes it unsuitable for sophisticated applications. As the distortions are time varying in nature, we propose a depth filtering scheme to reduce the distortion by exploiting the temporal information and color information present in a scene. The proposed algorithm increases the point to point correspondence of the depth map with its RGB image by a large extent. As the decomposition algorithm is performed on each pixel location separately, the execution of the algorithm can be performed using parallel processing.
(r)
(a)-(c) RGB video frames of static scenes and dynamic scene; (d)-(j) corresponding raw depth map of the scenes; (g)-(i) modified depth maps using proposed algorithm;(j)-(l) zoomed portions of the RGB frames; (m)-(0) zoomed portions of the corresponding raw depth map; (p)-(r) zoomed portions of the modified depth maps. Fig. 2.
III.
CONCLUSION
EXPERIMENTAL RESULTS
We have tested the algorithm both for the static scenes and dynamic scenes. In fig. 1, we show that the outputs of the decomposition algorithm on the RGB video and its corresponding depth video. As stated in sec. 2, the feature part of the RGB video contains the motion information and the feature part of the depth video contains the distortions and the depth of moving objects as shown in figs. l (c) and (g ) . As there is no noise in the color channel, it is fairly simple to construct the mask of the moving object and to rectify the depth of the moving object. For static scene, the visually similar part
REFERENCES [1]
J. Zhu, L. Wang, R. Yang, and 1. Davis, "Fusion of time-of-flight depth and stereo for high accuracy depth maps," in Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on.
2008, pp. 1-8.
25
IEEE,
2015 Third International Conference on Image Information Processing [2]
[3]
D. Weinshall, "Qualitative depth from stereo, with applications," Com puter Vision, Graphics, and Image Processing, vol. 49, no. 2, pp. 222241, 1990.
[10]
F. H. Sinz, J. Q. Candela, G. H. Baku, C. E. Rasmussen, and M. O. Franz, "Learning depth from stereo," in Pattern Recognition. Springer, 2004, pp. 245-252.
I. Gheta, C. Frese, M. Heizmann, and J. Beyerer, "A new approach for estimating depth by fusing stereo and defocus information." GI Jahrestagung (1), vol. 7, pp. 26-31, 2007.
[11]
K. Khoshelham and S. O. Elberink, "Accuracy and resolution of kinect depth data for indoor mapping applications," Sensors, vol. 12, no. 2, pp. 1437-1454, 2012.
[4]
A. K. Dalrnia and M. Trivedi, "Depth extraction using a single moving camera: an integration of depth from motion and depth from stereo," Machine Vision and Applications, vol. 9, no. 2, pp. 43-55, 1996.
[12]
I. Oikonomidis, N. Kyriazis, and A. A. Argyros, "Efficient model-based 3d tracking of hand articulations using kinect." in BMVC, vol. 1, no. 2, 2011, p. 3.
[5]
S. Bhattacharya, S. Gupta, and K. Venkatesh, "High accuracy depth filtering for kinect using edge guided inpainting," in Advances in
[13]
L. Chen, H. Lin, and S. Li, "Depth image enhancement for kinect using region growing and bilateral filter," in Pattern Recognition (ICPR), 2012 21st International Conference on. IEEE, 2012, pp. 3070-3073.
[14]
P. Lai, D. Tian, and P. Lopez, "Depth map processing with iterative joint multilateral filtering," in Picture Coding Symposium (PCS), 2010. IEEE, 2010, pp. 9-12.
[15]
I. W. Selesnick and I. Bayram, "Total variation filtering," Available: http://citeseerx.ist.psu.edu/viewdoc/download, 2009.
[16]
S. Bhattacharya, R. Yadav, V. Narendra, K. Venkatsh, and S. Gupta, "To tal variation based fast video decomposition for artifact restoration," in
Computing, Communications and Informatics International Conference on.
[6]
IEEE, 2014, pp. 868-874.
D. Scharstein and R. Szeliski, "High-accuracy stereo depth maps using structured light," in Computer Vision and Pattern Recognition, 2003. Proceedings. 2003 IEEE Computer Society Conference on, vol. 1. IEEE, 2003, pp. 1-195.
[7]
S. Birchfield and C. Tomasi, "Depth discontinuities by pixel-to-pixel stereo," International Journal of Computer Vision, vol. 35, no. 3, pp. 269-293, 1999.
[8]
H. H. Baker, "Depth from edge and intensity based stereo." DTIC Document, Tech. Rep., 1982.
[9]
M.
Digital Signal Processing (DSP), 2015 IEEE International Conference on.
Subbarao and G. Surya, "Depth from defocus: a spatial domain approach," International Journal of Computer Vision, vol. 13, no. 3, pp. 271-294, 1994.
26
IEEE, 2015, pp. 1152-1155.